Building a Reinforcement Learning Environment

RL Applied to the Real World
From AlphaGo to Atari, Reinforcement Learning (RL) has shown exceptional progress in the gaming arena. Designing an RL environment for such tasks is relatively simple, as the training can be performed in the target environment without many constraints. When working with real-world tasks, designing the training environment is one of the main challenges. When applying RL to industrial tasks, there are mainly three ways of designing the training environment:
- Using the real system: RL can be trained directly in the target environment, removing the need for designing a simulation and later transferring the knowledge to the industrial environment. Nonetheless, this approach poses several issues such as safety constraints, large financial costs, and long training times.
- Using an industrial simulator: Instead of directly training on the real system, one can use an existing industrial simulator. Most of these simulators have powerful physics engines capable of mimicking the real system with great precision. However, said simulators generally require the purchase of software licenses, which limits the number of simulations that can be run in parallel. Further, they may not provide APIs allowing external control, thus making it more difficult to integrate with the RL training code.
- Building a custom simulation environment: this approach offers greater flexibility with the cost of having to model the whole environment from scratch. This is the approach we are using at MakinaRocks.
This blog post will share the process of building our custom RL training environment and some ways it can be used.
The Problem

Off-line programming (OLP) is a robot programming method that lowers the production stoppage time when compared to online teaching. This is done by generating the robot’s path using a high-fidelity graphical simulation (digital twin) and later calibrating the output path to the real robot. The current OLP methods still rely on manual labor and can take several months to be completed, thereby discouraging changes to the production line, which may incur large costs. Our goal is to reduce the time needed to produce optimal robot paths by applying Reinforcement Learning. For more information about MakinaRocks’s current RL applications, please check our blog post (KR).
The Training Environment
For the training environment, we defined the following requirements:
- Multi-Platform: our application should run on a large variety of operating systems (Windows, MacOS, Linux).
- Easily parallelable: parallelizing the training environment is one of the most effective ways to speed up the training procedure. We want to build an environment that can be compiled into a small executable and generate as many instances as supported by the hardware. The process of parallelizing our environment is explained in detail in our technical blog post (KR).
- Ability to integrate with real hardware: as we are trying to solve a real-world problem, it is paramount that our solution can be applied to real robots without many adaptations.
- Ability to integrate with MakinaRocks’s Reinforcement Learning Library (RLocks): we developed our own reinforcement learning library (RLocks), which allows our team to seamlessly apply several state-of-the-art RL algorithms to a given task. Being able to integrate our environment with RLocks can speed up the time taken to test various RL approaches.
Environment Diagram
Based on those requirements, we developed the following modules:
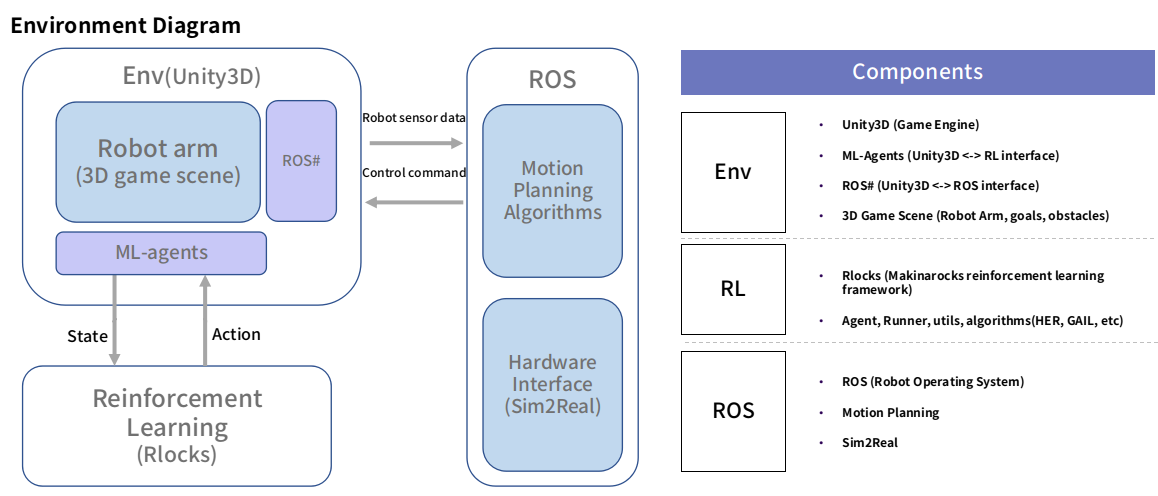
- Unity3D: a 3D game engine capable of rendering environments with high fidelity. Recent versions also added an updated physics engine with new components such as ArticulationBody, which is able to simulate kinematic chains with realistic and physically accurate movements. We use Unity as a physics simulator and 3D visualizer for our environment.
- RLocks: RLocks is MakinaRocks’s Reinforcement Learning library. It was created to allow the application of several state-of-the-art algorithms to the same task without extra work. It allows fast prototyping and to compare the performance of different approaches.
- ML-Agents: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents. We use it as a way to communicate between the Unity3D environment and RLocks algorithms.
- ROS: ROS(Robot Operating System) is an open-source meta-operating system for robots. It contains a set of tools, software, and hardware abstractions such as low-level drivers, inter-process communication, package management. etc. ROS allows us to create an interface between the simulated environment and real-robots. It also provides several open-source packages that can be used to complement and aid reinforcement learning control.
- ROS#: ROS# is a set of open-source software libraries and tools in C# for communicating with ROS from .NET applications, in particular Unity. We created custom messages and services that can send any needed information back-and-forth between Unity and ROS.
Environment Versions
Building the environment was an iterative process. As we learned more about the real process and fine-tuned our requirements, we also changed the training environment to better match said requirements.
The first version of our environment was built on Unity 2018.4 and used a simple 4 degrees of freedom (DOF) robot, which was controlled by applying torques directly to its joints. However, our application is more concerned about the joint positions than the torque applied to them. Also, most of the industrial robots have at least 6 DOF.

Therefore, we updated our environment to use a simple 6 DOF robot, which was controlled by directly setting the desired end-effector pose. This control value was then transformed into the joint space using an Inverse Kinematics module. Nonetheless, both the robot kinematic chain and motion were not realistic enough.

This led us to update the Unity version used in our project to version 2020.1. This Unity release has an updated physics engine with some new additions focused on robotics, namely PhysX articulation joints. This new joint type allowed us to realistically simulate kinematic chains and their motion. In addition, we updated our environment with a simulated version of the Universal Robots’ UR3e, which was controlled by setting the desired joint positions and velocities directly. Finally, we added a direct connection to ROS.

Even though the environment V3 used a real robot, it still could not match the complexities of robots found in large industries. Hence, we decided to change the robot model to a Kuka KR150, which is used in several industrial applications such as welding and painting. Moreover, we added a spot welding end-effector. These changes were important for us to visualize how the robot kinematic chain and size impacts the agent’s performance.

Example Application - Imitation Learning
The flexibility of our training environment allows us to efficiently apply a large variety of algorithms. In this blog post, we will describe one of them.
Imitation learning (IL) is a field that tries to learn how to perform a task based on “expert” demonstrations. Generative Adversarial Imitation Learning (GAIL)[1] is one of the most famous IL algorithms. In a similar way to Generative Adversarial Networks[2], it trains a “Discriminator” that learns to differentiate between expert trajectories and the agent trajectories. At the same time, the agent is trained to maximize the discriminator error, i.e. it learns how to fool the discriminator by “imitating” the expert. Despite being able to learn from a small number of expert trajectories, increasing the number of demonstrations, or performing data augmentation has been shown to improve GAIL’s performance[3]. When working with real robots, however, obtaining enough expert trajectories can pose a number of issues.
If moving the robot manually, the quality and the consistency of the expert trajectories can be degraded. Due to the need for a large amount of data, the operator fatigue or lack of concentration can lead to sub-optimal trajectories. Controlling a robot in the joint space can be counter-intuitive and hard to manually control, leading to the usage of external proxies such as virtual reality controllers[4], exoskeletons[5], or full-body tracking[6] as a way to simplify the process for the operator. Nonetheless, such devices add extra costs and require time for developing and setting up the whole system. Finally, when the expert trajectories and the agent trajectories come from different domains, the discriminator can easily overfit to small differences between both domains, making it impossible for the agent to learn[7].
Our framework can overcome said issues by automating the expert trajectory generation using state-of-the-art classical approaches included in ROS. MoveIt is an open-source ROS package that can perform motion planning, manipulation, collision avoidance, control, inverse kinematics, and 3D perception. We developed a ROS hardware interface to work as a middleware between MoveIt and Unity3D to isolate both modules from each other. In other words, the MoveIt side sent the same commands it would send to a real robot, while the Unity side received the same commands it would receive from the RL agent. We were then able to run MoveIt in a loop, while sampling the commands on the Unity side, enabling both expert and agent trajectories to be sampled from the same domain. As the whole process is automated, one can generate as many expert trajectories as needed.
We sampled expert trajectories for 6 hours (approximately 1000 trajectories) and ran the GAIL training for 24 additional hours. The result of this training can be seen in the video below:
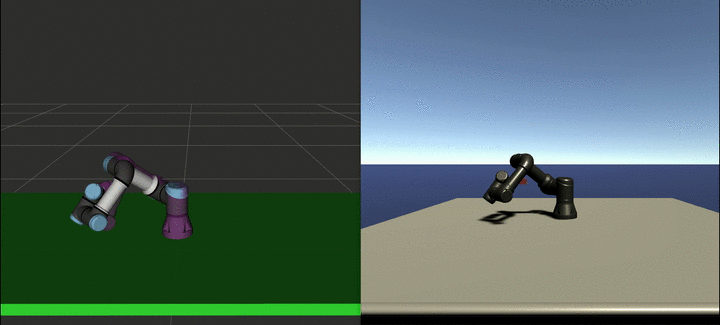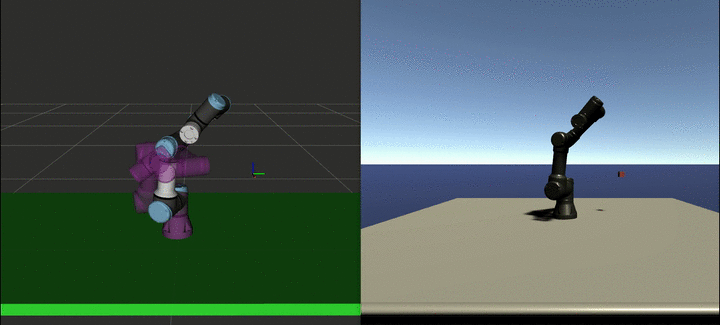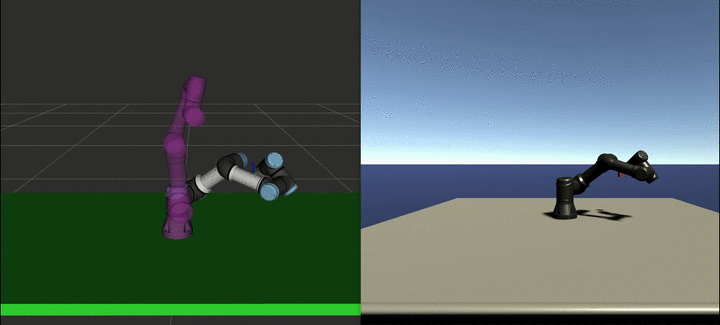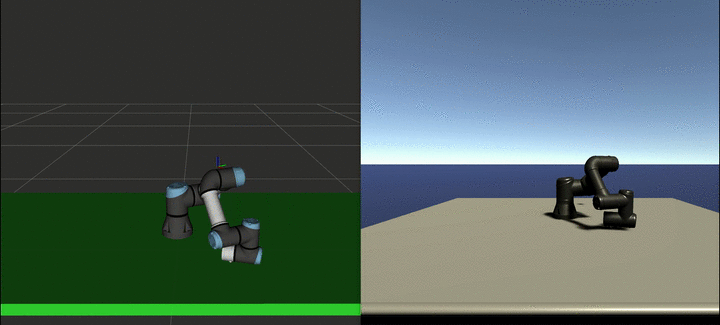

Depending on the task complexity, planning with MoveIt can take from a few seconds to several minutes. On the other hand, the agent can generate the path in real-time. Moreover, this policy can be further improved using curriculum learning, so that it can perform more complex tasks.
What is Next?
This blog post shared how we developed our custom reinforcement learning environment and one of our applications. We plan to add more functionalities and applications as our research progresses. We look forward to sharing more of MakinaRocks’s technical developments in the near future.
References
- [1] Ho, Jonathan, and Stefano Ermon. “Generative adversarial imitation learning.” Advances in neural information processing systems. 2016.
- [2] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems. 2014.
- [3] Ding, Yiming, et al. “Goal-conditioned imitation learning.” Advances in Neural Information Processing Systems. 2019.
- [4] Zhang, Tianhao, et al. “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation.” 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
- [5] Porges, Oliver, et al. “A wearable, ultralight interface for bimanual teleoperation of a compliant, whole-body-controlled humanoid robot.” Proceedings of ICRA-International Conference on Robotics and Automation. 2019.
- [6] Jha, Abhishek, et al. “Imitation Learning in Industrial Robots: A Kinematics based Trajectory Generation Framework.” Proceedings of the Advances in Robotics. 2017. 1-6.
- [7] Zolna, Konrad, et al. “Task-relevant adversarial imitation learning.” arXiv preprint arXiv:1910.01077 (2019).
Explore more
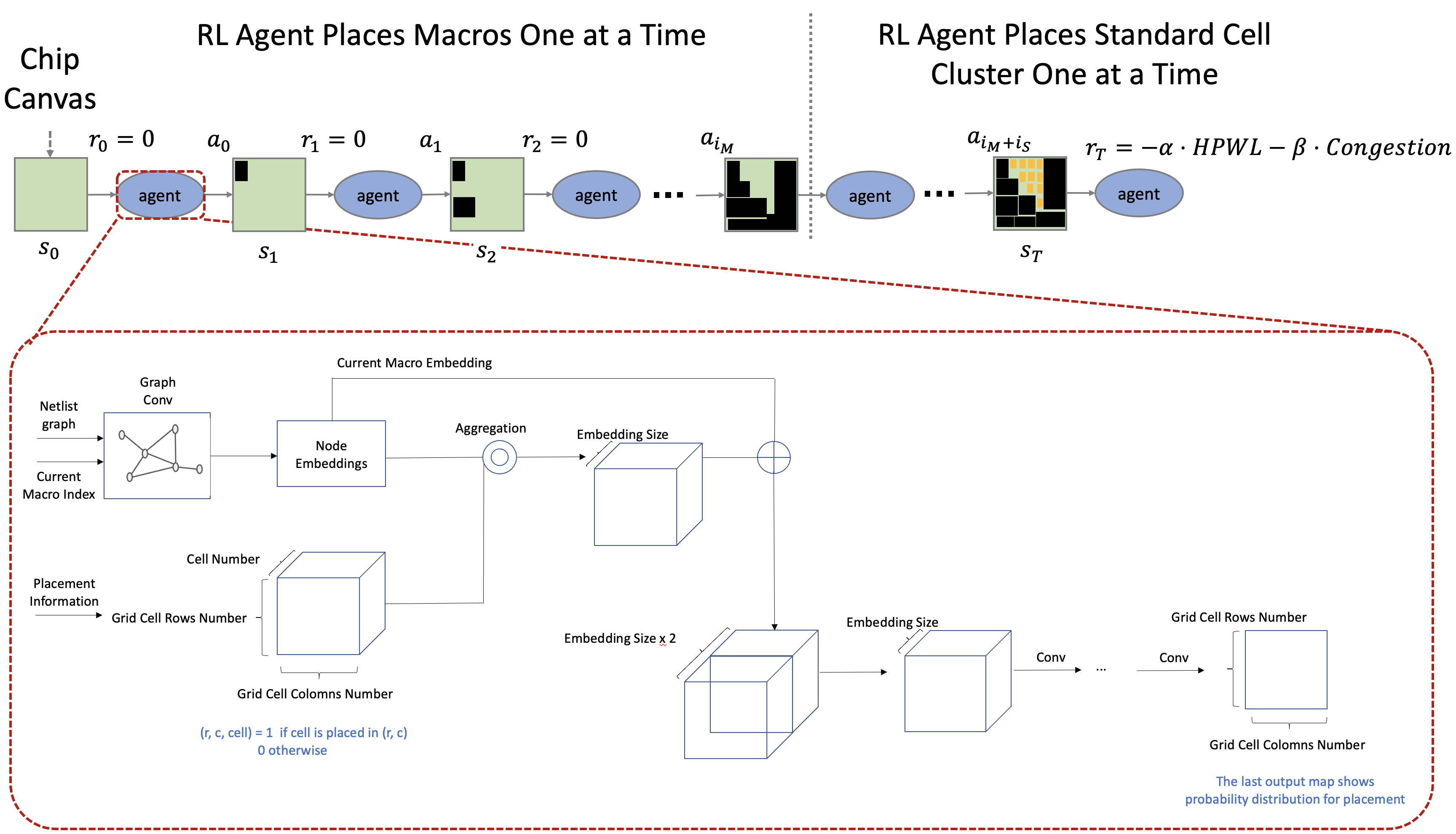
Application Specific Integrated Circuit (ASIC) Floorplan Automation - Part I
MakinaRocks’ Combinatorial Optimization Problem (COP) team is working on a floorplan automation project, which automates component placement on Application-Specific Integrated...

주문형 반도체 (ASIC) Floorplan 자동화 - Part III
Related to 강화학습, 산업의 난제에 도전하다! - ASIC 반도체 설계 (Floorplan) 자동화 (Naver Deview 21 발표 영상) ASIC-Chip-Placement 1부 ASIC-Chip-Placement...

Comments