실시간 데이터 검증하기

마키나락스는 제조업에서 실시간으로 생산 장비와 공정의 고장 및 이상을 사전에 예측하는 이상탐지 시스템을 제공하고 있습니다. 이상탐지 시스템을 적용하고자 하는 제조 생산 현장은 제품 및 공정의 변화가 잦은 곳이 많습니다. 공정이 변하면 데이터 분포가 달라지기 때문에, 사전에 학습된 모델이 적용하려는 시점에는 정상 작동하기 어렵습니다. 이런 문제를 해결하기 위해 학습과 추론이 동시에 가능한 코드 형태로 모델을 배포하고, 배포된 동안 새롭게 수집한 데이터를 이용해 모델을 학습합니다. 학습된 모델이 등록되면 실시간으로 새롭게 입력되는 데이터에 대해 추론합니다.
실시간 추론 서비스를 제공하는 모델은 배포된 코드와 함께 현장에서 수집한 학습 데이터로 완성됩니다 [1]. 모델이 안정적으로 학습되고 추론하기 위해서는 코드뿐만 아니라 데이터에 대해서 유효성 테스트가 필요합니다. 이번 포스트에서는 실시간으로 입력돼 학습과 추론에 사용되는 데이터의 유효성을 확인할 수 있는 방법에 대해 소개드리겠습니다.
Why data need test?
예상과 다르게 입력된 데이터로 모델을 학습, 추론한 경우 의도와 다른 결과를 출력할 수 있습니다.
예를 들어, Numeric 데이터 입력을 받는 연산 코드에서 Boolean 데이터 False가 입력됐을 경우를 생각해보겠습니다.
입력된 데이터의 Type이 다르지만 Python은 False를 0으로 변환해 연산한 결과를 출력합니다.
이 경우 코드가 작동하는데 문제 없기 때문에, 나중에 출력 결과를 통해 디버깅하는 것은 어렵습니다.
이와 같은 문제는 데이터 유효성 테스트를 통해 미리 방지할 수 있습니다.
이번 포스트에서는 데이터를 테스트하는 과정 중 아래 3가지를 중심으로 소개해 드리겠습니다.
- Data Schema
- 데이터의 타입, 범위와 필수 속성 포함 여부
- Feature Ordering
- 데이터의 속성값 순서
- Dataset Shift
- 데이터 분포 변화 여부
1. Data Schema
모델의 입력으로 0 ~ 1 사이의 양수 값을 갖는 센서 데이터가 들어오는 상황을 생각해보겠습니다. 하지만 노이즈로 인해 음수 값이 입력될 수 있는 상황입니다. 음수 값을 그대로 입력 데이터로 사용할 경우 모델은 신뢰도가 낮은 결과를 출력합니다.
이런 경우 값의 범위를 제한하는 것으로 문제를 해결할 수 있습니다. 나아가 값의 범위뿐만 아니라, 올바르지 않은 타입의 데이터가 들어오거나 필요한 값이 들어오지 않는 상황을 확인하는 것도 필요합니다. 이렇게 Data Schema로 데이터의 타입, 범위와 필수 속성 포함 여부를 명시하고, 명시한 Data Schema에 맞는 데이터가 입력됐는지 확인하는 검증 과정을 소개해 드리겠습니다.
1.1 Example of Invalid Data
단순한 Feature Engineering 예시를 통해 검증 과정을 소개해 드리겠습니다.
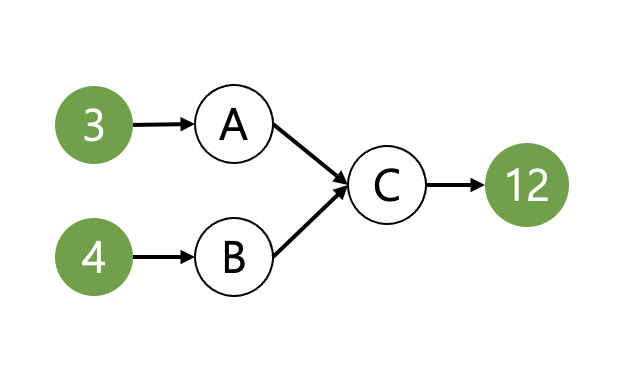
Sample의 Feature A와 Feature B 속성을 이용해 새로운 Feature C를 만들어 내는 Feature Engineering 코드가 있습니다.
Numeric 데이터 Feature A와 Feature B에 대해 곱하기 연산을 하여 Feature C를 만든다고 가정해봅시다.
def make_feature_c(sample):
feature_a = sample["feature_a"]
feature_b = sample["feature_b"]
return feature_a * feature_b
실시간으로 데이터가 입력되는 상황에서 Feature A 또는 Feature B가 정상적으로 들어오지 않는 경우를 생각해 보겠습니다.
1.1.1 Example of Invalid Data Type
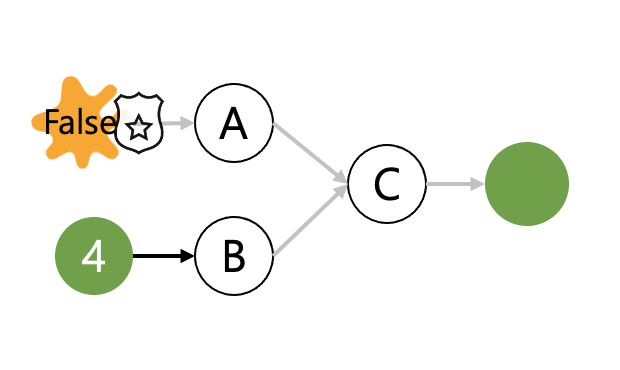
예를 들어, Feature에 Numeric 대신 Boolean 값이 들어온 상황입니다.
>>> data = {
"feature_a": False,
"feature_b": 4,
}
>>> feature_c = make_feature_c(data)
>>> feature_c
0
위의 예시에서는 Engineering 할 Feature에 Boolean 값이 들어오면서 예상치 못한 Feature C가 만들어지게 됩니다.
잘못 입력된 Feature A가 0이라는 의도하지 않은 결과를 만들고 다음 프로세스까지 영향을 미치게 됩니다.
이 경우 코드가 작동하는데 문제 없기 때문에, 나중에 출력 결과를 통해 디버깅하는 것은 어렵습니다.
1.1.2 Example of Invalid Data Range
Feature A와 Feature B 값의 범위를 양수로 한정한 경우에 대해 예를 들어보겠습니다.
>>> data = {
"feature_a": -1,
"feature_b": 4,
}
>>> feature_c = make_feature_c(data)
>>> feature_c
-4
make_feature_c 함수에서 값의 범위를 확인하지 않아 음수가 들어온 상황에도 함수가 동작합니다.
이 경우도 Type이 잘 못 입력된 상황과 동일하게 작동하는데 문제 없기 때문에, 나중에 출력 결과를 통해 디버깅하는 것은 어렵습니다.
1.1.3 Example of Invalid Data Properties
데이터에 Feature A가 포함되지 않은 경우에는 함수를 실행하는 중간에 프로세스가 중단됩니다.
>>> data = {
"feature_b": 4,
}
>>> feature_c = make_feature_c(data)
KeyError Traceback (most recent call last)
...
KeyError: 'feature_a'
기본적으로 데이터에 의도한 Feature가 모두 있는지, 있다면 올바른 Type으로 정의되어 있는지, 그리고 값이 예상 범위 내에 포함되는지 등 데이터에 대한 검증을 미리 수행하는 것이 결과의 신뢰성을 높이는 데 많은 도움이 됩니다.
앞서 언급한 데이터의 여러가지 속성들을 스키마로 사전 정의하여 입력 데이터에 대한 검증을 손쉽게 시행할 수 있습니다.
1.2 Json Schema
Json Schema를 활용해 데이터의 약속된 형태를 표현할 수 있습니다.
Json Schema란 JSON형식으로 데이터의 구조를 설명합니다 [2].
의도하는 데이터의 형태를 표현하고, 새로 들어오는 데이터가 이 형태에 맞는지 검증합니다.
Json Schema의 주요 요소를 소개해 드리겠습니다.
- “type”
- Schema에서 데이터 타입을 지정합니다.
string,number,object,array,boolean,null- 공식 페이지 - type 참고
- “properties”
object데이터의 속성을 구체적으로 정의합니다.- 공식 페이지 - properties 참고
- “required”
object데이터가 필수로 가져야하는 속성을 지정합니다.- 공식 페이지 - required properties 참고
앞에서 정의한 make_feature_c 함수의 입력 상황에 적용할 수 있는 Json Schema를 보여드리겠습니다.
서비스에 입력되는 데이터가 Feature 이름과 값이 맵핑되어 있는 Python dict 자료형이라고 가정해봅시다.
여기서 dict는 JSON 형식 중 “object”와 호환되는 자료 구조로 스키마의 type Field 값을 object로 선언합니다.
데이터는 Feature A와 Feature B를 필수로 가져야하므로 required Field에 ["feature_a", "feature_b"]를 추가합니다.
또한 두 Feature 모두 Numeric 데이터를 가지므로 properties Field type을 "number"로 기입합니다.
마지막으로 두 Feature를 양수의 범위로 한정하기 위해 properties Field의 exclusiveMinimum을 0으로 설정합니다.
{
"type": "object",
"required": ["feature_a", "feature_b"],
"properties": {
"feature_a": {
"type": "number",
"exclusiveMinimum": 0,
},
"feature_b": {
"type": "number",
"exclusiveMinimum": 0,
}
}
}
Feature A와 Feature B처럼 중복되는 Schema는 아래와 같이 한번의 정의 후 재사용할 수 있습니다.
{
"definitions": {
"pos_num_feature": {
"type": "number",
"exclusiveMinimum": 0
}
},
"type": "object",
"required": ["feature_a", "feature_b"],
"properties": {
"feature_a": { "$ref": "#/definitions/pos_num_feature" },
"feature_b": { "$ref": "#/definitions/pos_num_feature" }
}
}
위에 설정한 검증 조건 외에 Feature마다 null 검증 조건을 표현할 수 있고, if-then-else 구조를 사용해 복잡한 조건부 구조 등을 표현할 수도 있습니다. (기타 예시)
1.3 Json schema validator
Python jsonschema 패키지를 활용해 입력된 dict 데이터가 유효한 구조로 정의되어 있는지 검증하는 예시를 보여드리겠습니다.
>>> from jsonschema import validate
>>> # Schema를 선언합니다.
>>> schema = {
"type": "object",
"required": ["feature_a", "feature_b"],
"properties": {
"feature_a": {
"type": "number",
"exclusiveMinimum": 0,
},
"feature_b": {
"type": "number",
"exclusiveMinimum": 0,
}
}
}
>>> # 유효한 Sample을 생성합니다.
>>> sample = {
"feature_a" : 3,
"feature_b" : 4,
}
>>> # 유효성 확인을 통과한 경우, 오류없이 통과합니다.
>>> validate(instance=sample, schema=schema)
>>> # 유효하지 않은 Type의 Sample을 생성합니다.
>>> sample = {
"feature_a" : False,
"feature_b" : 4,
}
>>> # 유효성 확인을 통과하지 못 한 경우, 오류와 함께 이유를 반환합니다.
>>> validate(instance=sample, schema=schema)
ValidationError: False is not of type 'number'
Failed validating 'type' in schema['properties']['feature_a']:
{'exclusiveMinimum': 0, 'type': 'number'}
On instance['feature_a']:
False
패키지를 이용해 데이터의 타입, 범위와 필수 속성 포함 여부를 검증할 수 있는 방법을 확인했습니다.
2. Feature Ordering
실시간으로 입력되는 데이터가 여러 Feature들로 구성되어 있다고 가정해보겠습니다. 이때 지속적으로 동일한 순서의 Feature가 입력되는지 확인하는 과정이 필요합니다.
실제 데이터를 전송하는 과정에서 지연으로 인해 Feature의 순서가 보장되지 않을 수 있습니다. 예를 들어, 각 Feature가 다른 경로를 통해 입력되는 경우를 생각해보겠습니다. 각각의 경로가 항상 동일한 순서로 데이터를 전송해 주어야 Feature의 순서가 유지됩니다. 하지만 모든 경로에서 데이터의 전송 순서를 제약하는 것은 까다로울 수 있습니다.
딥러닝 모델은 입력 데이터의 Feature Shape만 동일하다면 추론을 통해 결과를 얻을 수 있습니다.
만약 Feature A, Feature B, Feature C의 순서가 보장되어야 하는 데이터가 Feature B, Feature C, Feature A 순서로 입력된다고 하더라도 모델은 문제없이 추론할 것입니다.
예를 들어, 3차원의 RGB 이미지로 학습한 모델에 BGR 순서의 이미지를 입력하는 것도 가능합니다.
이런 경우 모델의 추론이 정상적으로 작동하므로 입력의 오류를 확인하는 것은 어렵습니다. 이러한 오류를 방지하기 위해서는 Feature Ordering에 대한 검증이 필요합니다.
2.1 Preprocessing for Validity
여러 경로에서 입력된 데이터를 pandas.DataFrame 형태로 변경하는 과정에서 전처리를 통해 Feature의 순서를 고정할 수 있습니다.
import pandas as pd
class ColumnAligner:
"""동일한 DataFrame의 column 순서를 보장합니다."""
def __init__(self) -> None:
self.column_alignment = None
def fit(self, df: pd.DataFrame) -> None:
"""fit하는 DataFrame의 컬럼 순서를 저장합니다.
Parameters
----------
df : pd.DataFrame
표준 컬럼 순서를 갖는 데이터.
"""
self.column_alignment = df.columns.tolist()
def transform(self, df: pd.DataFrame) -> pd.DataFrame:
"""저장된 컬럼 순서로 순서를 변경합니다.
모든 컬럼을 포함하고 있을 때를 가정합니다.
Parameters
----------
df : pd.DataFrame
컬럼 재배치 대상이 되는 데이터.
Returns
-------
pd.DataFrame
컬럼 재배치된 데이터.
"""
return df.loc[:, self.column_alignment]
전처리 클래스의 fit 함수를 통해 학습 데이터의 컬럼 순서를 저장하고, transform 함수를 통해 데이터의 컬럼을 올바른 순서로 배치합니다.
>>> # train_data를 기준으로 test_data의 col 순서를 맞춥니다.
>>> column_aligner = ColumnAligner()
>>> column_aligner.fit(train_data)
>>> test_data = column_aligner.transform(test_data)
컬럼의 순서를 유지할 수 있는 전처리 클래스 하나를 추가하는 것으로 오류를 예방할 수 있습니다.
3. Dataset Shift
제조 현장에서 취득한 월요일부터 일요일까지의 일주일 데이터를 생각해보겠습니다. 이때 공장 휴일인 일요일에는 기계가 가동되지 않지만 센서가 데이터를 취득하고 있다고 가정해봅시다. 일요일에 취득한 데이터는 유효하지 않으며, 또한 월요일부터 토요일까지의 데이터와는 다른 분포를 갖게될 것입니다. 이렇게 데이터의 성격이 중간에 달라지는 현상을 Dataset Shift라고 합니다 [4].
3.1 Example of Invalid Dataset

시계열 데이터는 [그림5]와 같이 데이터 중 가장 오래된 부분을 Train Dataset으로, 나머지 뒷 부분을 Validation Dataset으로 분할해 사용합니다. 월요일부터 일요일까지 일주일 데이터를 이용해 모델을 학습 및 검증하는 상황을 가정하겠습니다.

Train Dataset : Validation Dataset 비율을 5 : 2로 할 경우, [그림6]과 같이 월요일부터 금요일까지 데이터를 Train Dataset으로, 토요일과 일요일 데이터를 Validation Dataset으로 사용하게 됩니다.
하지만 이때 휴일인 일요일이 Validation Dataset에 포함되는 것이 적합한 분할일까요? 이 경우 일요일을 제외하고 토요일까지의 데이터만 사용하는 것이 적합합니다.
Validation Dataset은 학습에 사용되지 않은 데이터로서 주로 학습된 모델을 평가하는 데 사용됩니다. Validation Dataset이 모델을 평가하는데 적절하지 않은 Dataset이었다면 어떻게 될까요? 모델에 대한 평가도 왜곡되고, 의도와 다른 결과를 출력해 비정상적인 작동을 하게 될 것입니다.
Dataset은 시스템의 전체적인 성능 안정성을 위해 검증되어야 합니다. 배포 환경의 상황을 모를 때 Dataset Shift 여부를 확인하는 과정에 대해 소개드리겠습니다.
3.2 t-test
Input Dataset에 대한 모델의 Output 분포 변화를 이용해 Dataset Shift 여부를 확인할 수 있습니다 [4]. 분포 변화를 확인하기 위해 통계적 검정방법 t-test를 이용합니다. t-test은 두 집단 간의 평균을 비교하는 방법으로 ‘두 집단의 평균이 차이가 없다’라는 귀무가설과 ‘두 집단의 평균이 차이가 있다’라는 대립가설 중 하나를 선택합니다. t-test로 구한 P-value는 귀무가설이 참일 때 결과값의 유의미한 정도를 나타냅니다. 보통 P-value가 0.05보다 작을 때 대립가설을 채택하며, P-value가 작을 수록 귀무가설이 유의미하지 않다고 할 수 있습니다.
Python scipy 패키지의 scipy.stats.ttest_ind를 이용해 임의로 생성한 서로 다른 두 데이터 분포를 비교해 보겠습니다.
t-test는 각 집단의 모분산이 같다고 가정합니다.
하지만 모분산에 대한 정보를 모르는 상황이 대부분이므로
Test 함수의 equal_var 속성 값을 False로 설정해 Welch’s t-test 방법을 사용합니다.
편의를 위해 본문에서 t-test로 표현하겠습니다.
>>> import numpy as np
>>> from scipy import stats
>>> # 평균 0, 분산 1인 Normal Distribution에서 샘플이 100개인 집단을 생성합니다.
>>> group_a = np.random.randn(100)
>>> # 평균 3, 분산 4인 Normal Distribution에서 샘플이 100개인 집단을 생성합니다.
>>> group_b = 3 + 2 * np.random.randn(100)
>>> # 두 집단을 비교합니다. 이때, 두 집단의 분산이 다를 것이라고 가정합니다.
>>> t_statistic, p_value = stats.ttest_ind(group_a, group_b, equal_var=False)
>>> # p_value가 0.05보다 작은 경우 평균이 다른 집단으로 판단합니다.
>>> if p_value < 0.05:
print("Means of the two groups are different.")
Means of the two groups are different.
3.3 Test Dataset Shift
이어서 t-test를 이용해 Dataset Shift 여부를 확인하는 과정을 소개해 드리겠습니다. 우선 1/2 시점을 기준으로 Dataset Shift가 발생하는 예시 데이터를 만들어 보겠습니다.
>>> # 평균 0, 분산 1인 Normal Distribution에서 샘플이 100개인 집단을 생성합니다.
>>> group_a = np.random.randn(100)
>>> # 평균 30, 분산 4인 Normal Distribution에서 샘플이 100개인 집단을 생성합니다.
>>> group_b = 30 + 2 * np.random.randn(100)
>>> # group_a와 group_b를 연결합니다.
>>> data = np.append(group_a, group_b)
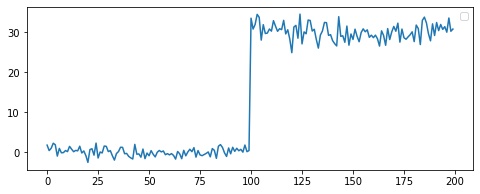
Dataset에서 한 시점을 기준으로 이전 시점 데이터를 Group-pre, 이후 시점 데이터를 Group-post로 표현하겠습니다. 시간이 지남에 따른 Dataset Shift 여부를 확인하기 위해 Group-pre와 Group-post에 대해 t-test를 진행합니다.
이때 집단을 구분하는 시점을 여러개로 두어 다양한 시점에서의 Dataset Shift를 확인할 수 있습니다. 시점을 정하는 방법으로 [그림8]과 같이 균등하게 구간을 나누는 방법을 사용할 수 있습니다. [그림8]은 예시 데이터에 대해 Dataset Shift 후보로 균등하게 분포한 4개 구간을 정의한 상황입니다.
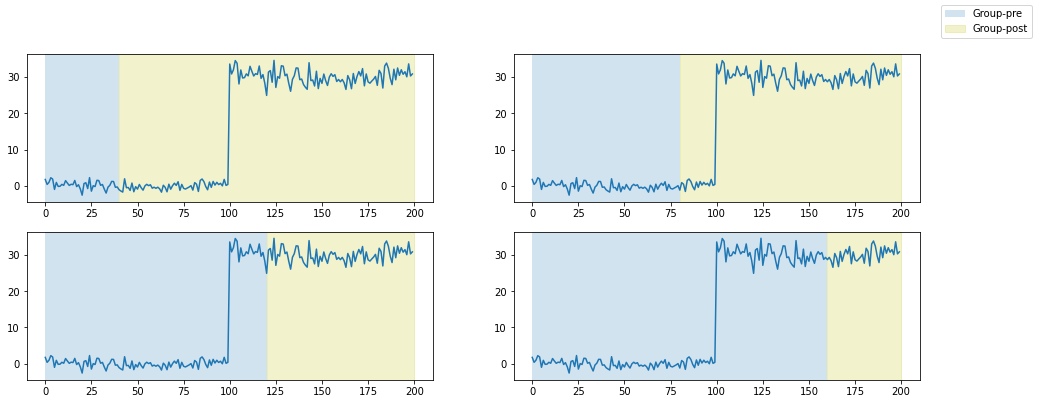
주어진 구간들에 대해 Dataset Shift를 검증할 수 있는 check_dataset_shift 함수를 정의해보겠습니다.
check_dataset_shift는 가장 낮은 P-value가 Threashold (0.05) 보다 작을 때, 해당 구간의 근처에서 Dataset Shift가 있어났다고 예측합니다.
[그림8]에서처럼 4개의 구간에 대해 데이터를 검증할 경우 2/5 또는 3/5 지점 근처에서 Dataset Shift가 일어났으리라 예측할 것 입니다.
# Dataset Shift가 예상된 경우 ValueError를 raise합니다.
def check_dataset_shift(
output: np.ndarray, # 평가 대상이 되는 Output
n_test_points: int = 4, # 구간 분할 횟수
) -> None:
# 구간 하나의 크기를 정합니다.
split_size = len(output) // (n_test_points + 1)
min_p_value = float("inf")
shift_point = None
for test_point in range(1, n_test_points + 1):
# Group-pre는 판단 시점 이전 데이터를 할당합니다.
# Group-post는 판단 시점 이후 데이터를 할당합니다.
group_pre = output[: split_size * test_point]
group_post = output[split_size * test_point :]
t_statistic, p_value = stats.ttest_ind(
group_pre,
group_post,
equal_var=False,
)
# 가장 작은 P-value와 해당 시점을 저장합니다.
if min_p_value > p_value:
min_p_value = p_value
shift_point = test_point
# 최소 P-value가 0.05보다 작을 때 Dataset Shift를 판단하고 ValueError를 raise합니다.
if min_p_value < 0.05:
raise ValueError(f"Expect dataset shift around {shift_point}/{n_test_points + 1}")
예시 데이터를 적용하면 아래와 같은 결과를 얻을 수 있습니다.
>>> # 예시 데이터를 4개 구간으로 나눠 Dataset Shift를 확인합니다.
>>> # 2/5 지점 근처에서 Dataset Shift가 일어났음을 예상할 수 있습니다.
>>> check_dataset_shift(data, n_test_points=4)
ValueError: Expect dataset shift around 2/5
t-test의 P-value를 통해 Dataset Shift를 검증하는 과정에 대해 소개드렸습니다.
4. Conclusion
이번 포스트에서 데이터 유효성 검증이 필요한 이유와 구체적인 검증 방법을 다뤄보았습니다. 데이터를 이용해 모델을 학습하는 머신러닝 특성상 코드뿐만 아니라 데이터의 유효성을 검증하는 과정이 반드시 필요합니다. 이번 포스트의 내용이 비슷한 문제를 고민하는 분들께 도움이 되길 바랍니다.
[1] Eric Breck Shanqing Cai Eric Nielsen Michael Salib D. Sculley, 2017, The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction.
[3] H. Khizou. “Unit Testing Data: What Is It and How Do You Do It?” winderresearch.com (accessed Apr. 13, 2021)
[4] M. Stewart. “Understanding Dataset Shift” towardsdatascience.com (accessed Apr. 13, 2021)
Explore more
Kubernetes기반의 Regression Test Pipeline을 구축하기
마키나락스는 AI 기술개발을 넘어서 AI 제품화과정으로 나아가고 있습니다. 제품화과정으로 나아가는 여정 속에서 재미있는 엔지니어링 이슈들이 생겼습니다. 제품의 실체화에 가까워질수록 시장에서...

Comments