Kubeflow/Katib의 안전한 사용과 커뮤니티를 위해 기여하기

마키나락스의 Platform 팀에서는 Kubeflow를 기반으로 하여 ML/DL 모델의 실험과 배포의 간극을 줄이는 MLOps 플랫폼을 개발하고 있습니다. Kubeflow는 ML Workflow 를 Kubernetes-native하게 실행하고 관리할 수 있는 플랫폼이지만, 아직 v1.0 이 released 된 지 약 1년 반 정도밖에 지나지 않은 프로젝트이기에 Kubernetes에 익숙하지 않은 Data Scientist, ML Engineer가 사용하기에는 부족한 점이 다수 존재합니다.
따라서 저희 Platform 팀에서는 Kubeflow의 여러 구성요소들을 활용하되, 특정 기능은 우회해서 사용하고, 또 특정 기능은 자체적으로 구현하여 적절히 커스터마이징하여 사용하고 있습니다. 또한 그중 Kubeflow 프로젝트에 보편적으로 반영할만한 기능들은 Pull Request (이하 PR)을 직접 생성하여 컨트리뷰션을 진행하고 있습니다.
본 포스팅에서는 Kubeflow의 구성요소 중 Hyperparameter Tuning and Neural Architecture Search 기능을 제공하는 Katib를 사용하며 겪었던 불편 사항과 해당 기능을 구현하여 오픈소스 프로젝트에 기여한 경험을 공유드리려고 합니다. Katib에 대한 보다 자세한 정보가 궁금하시다면 다음 공식 문서를 확인해 주시기 바랍니다.
컨트리뷰션 배경
Katib
마키나락스에서는 Kubeflow와 Katib를 통합하여, 각 팀원의 로컬 머신 내에서 프로세스 단위의 parallelized hyperparmeter optimization(이하 HPO)가 아닌, 약 10 개의 GPU 서버를 통합한 사내 Kubernetes cluster 에서 pod 단위의 parallelized HPO을 수행하고 있습니다.
HPO의 성능을 끌어올리는 가장 흔한 방법으로는 대규모의 hyperparameter search space에 대해 많은 양의 컴퓨팅을 수행하는 방법을 사용하기에, 고스펙의 서버와 많은 시간을 필요로 합니다. 따라서 흔히 사용하는 HPO package인 Scikit-Optimize, Hyperopt, Optuna를 로컬 머신의 제한된 스펙 내에서 수행하는 경우 상당한 시간 소모가 불가피합니다. 하지만 Kubernetes와 같은 container orchestration system을 활용해 node 단위의 병렬 작업과 리소스 관리 최적화 및 스케줄링을 자동화한다면 훨씬 효율적인 실험을 수행할 수 있습니다.
물론 Optuna와 Ray-tune을 비롯한 HPO package들에서도, 다수의 서버를 cluster로 구성하거나, 혹은 기존 Kubernetes cluster에서 worker를 나누어 병렬 작업을 수행할 수 있는 기능을 지원하고 있습니다. 하지만 이들은 처음부터 Kubernetes native하게 설계되지 않은 프로젝트이기 때문에 Kubernetes cluster에서 사용하기에는 다소 활용도가 떨어지는 부분이 있습니다.
예를 들어 Optuna를 Kubernetes에서 사용하기 위해서는 다음과 같은 manifests를 배포 및 관리해야 하며, HPO를 담당하는 python 소스 코드를 추가한 도커 이미지를 필요로 합니다. 따라서 실험 중간에 hyperparameter search space를 변경하고 싶은 경우, 사용자는 python 소스 코드 수정, 도커 이미지 재빌드 후 재배포, manifests 중 worker Job 재배포의 모든 과정을 항상 수행해야 합니다. 아직은 Kubernetes의 custom resource 형태로 Optuna의 HPO 관련 로직을 제어할 수 있는 기능이 제공되지 않아, Kubernetes API로는 다양한 요청을 할 수 없기 때문에 발생하는 이슈입니다.
Katib는 이러한 문제를 효과적으로 해결하기 위해 시작된 프로젝트입니다.
Katib는 자체적으로 hyperparameter search algorithm을 구현하기도 하지만, 가장 큰 특징은 Scikit-Optimize, Hyperopt, Chocolate, Optuna와 같은 외부 라이브러리들의 기존 method들을 쉽게 통합할 수 있는 인터페이스를 제공한다는 점입니다.
인터페이스에 맞게 통합할 때 필요한 가이드도 자세히 제공하고 있으며, 실제로 이에 맞게 Scikit-Optimize, Chocolate, Optuna 등의 구현체가 Katib에 통합되어 있습니다.
즉, Katib는 hyperparameter search algorithm의 구현체들을 모아둔 프로젝트라기보다는, 구현체들이 Kubernetes 내의 자원들을 효율적으로 사용하며 HPO를 수행할 수 있도록 API 서비스화를 담당하며, 서비스를 안정적으로 제공할 수 있는 인프라를 제공하는 프로젝트에 가깝다고 표현할 수 있습니다.
Kubernetes에 익숙하신 독자분들이라면 Kubernetes에서는 CRI, CNI, CSI 만을 지원하여, 다양한 container-runtime, network, storage vendor를 plugin의 형태로 통합할 수 있는 인터페이스를 제공하는 컨셉과 유사하다고 보실 수도 있습니다.
하지만 아직 Katib는 이제 막 v0.12.0 release를 앞두고 있는 한창 발전해나가는 프로젝트이기에, 마키나락스에서는 Katib를 사용하며 여러 가지 이슈를 맞닥뜨리게 되었습니다.
이슈 상황
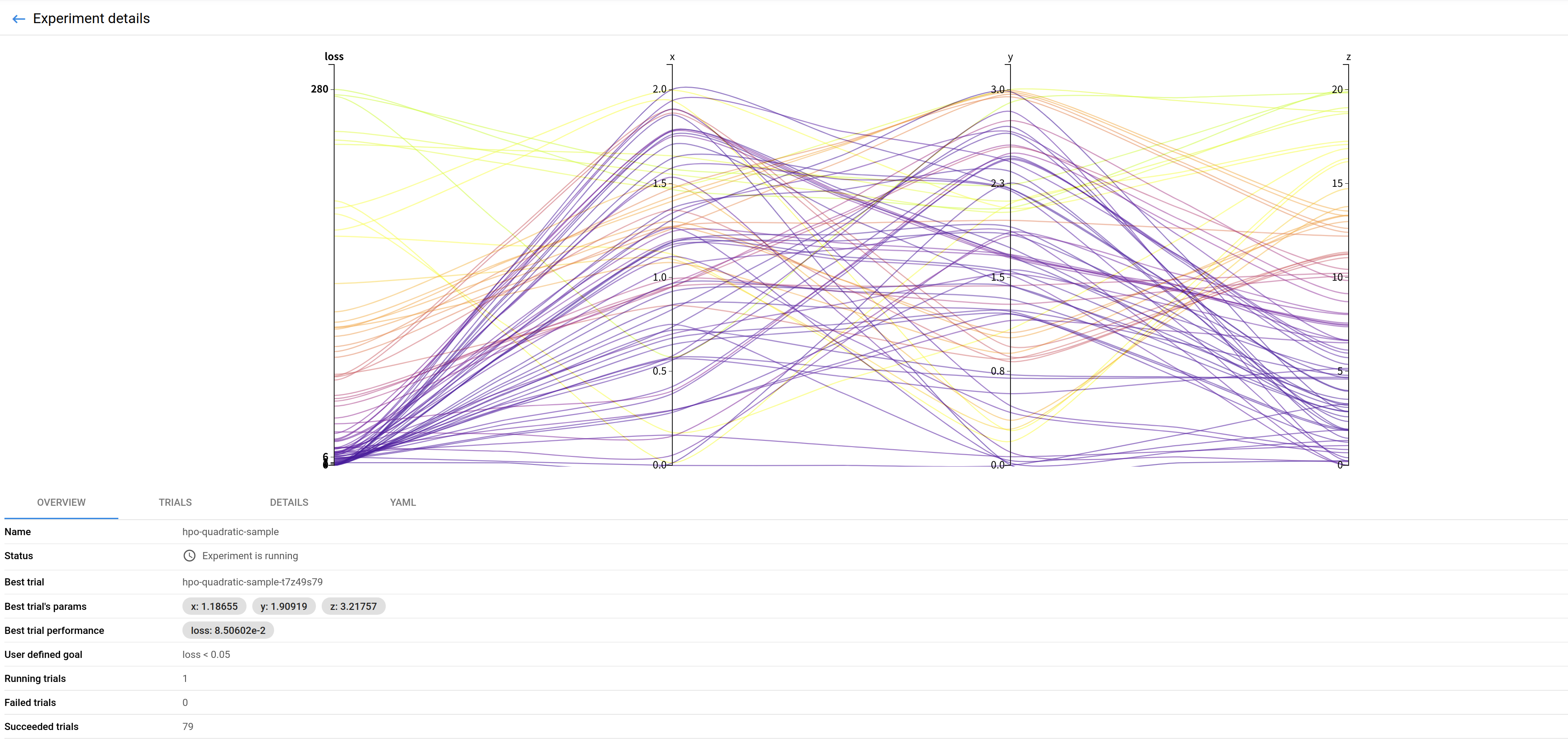
Katib는 HPO 한 세트를 Experiment라는 custom resource로 정의하고 관리하고 있습니다.
따라서 Kubernetes의 다른 custom resource 관리 방식과 동일하게, 사용자가 Experiment를 생성하기 위해서는 아래와 같이 정해진 형태의 yaml 혹은 json 파일을 생성하여 Kubernetes API Server로 생성 요청을 보내야 합니다.
# Sample Experiment with TPE algorithm
# ref) https://github.com/kubeflow/katib/blob/master/examples/v1beta1/tpe-example.yaml
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
namespace: kubeflow
name: tpe-example
spec:
objective:
type: maximize
goal: 0.99
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- Train-accuracy
algorithm:
algorithmName: tpe
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
parameters:
- name: lr
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.03"
- name: num-layers
parameterType: int
feasibleSpace:
min: "2"
max: "5"
- name: optimizer
parameterType: categorical
feasibleSpace:
list:
- sgd
- adam
- ftrl
trialTemplate:
primaryContainerName: training-container
trialParameters:
- name: learningRate
description: Learning rate for the training model
reference: lr
- name: numberLayers
description: Number of training model layers
reference: num-layers
- name: optimizer
description: Training model optimizer (sdg, adam or ftrl)
reference: optimizer
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: training-container
image: docker.io/kubeflowkatib/mxnet-mnist:v1beta1-45c5727
command:
- "python3"
- "/opt/mxnet-mnist/mnist.py"
- "--batch-size=64"
- "--lr=${trialParameters.learningRate}"
- "--num-layers=${trialParameters.numberLayers}"
- "--optimizer=${trialParameters.optimizer}"
restartPolicy: Never
하지만, Katib에서 내부적으로 정해둔 규칙에 어긋난 형태로 Experiment 생성 요청을 수행할 경우, 실제로는 Experiment가 정상적으로 생성되지 않았음에도 불구하고 사용자가 보기에는 해당 Experiment의 상태가 Running 혹은 Creating으로 보여 제대로 동작하는 것으로 착각하게 되는 문제가 자주 발생하였습니다.
그 중 저희가 자주 겪었던 문제 상황의 예를 들면 다음과 같습니다.
- 1)
Experiment의 이름을 정해진 규칙에 어긋나게 생성한 경우 - 2)
Experiment의suggestion algorithm관련 필드를 잘못 입력한 경우 - 3)
Experiment의primary-container필드를 잘못 입력한 경우 - 4)
Experiment생성 시sidecar.istio.io/inject: "true"를 명시하지 않은 경우
Kubernetes, Kubeflow 그리고 Katib에 익숙한 사용자라면 katib-controller를 비롯한 여러 구성 요소들의 로그를 일일이 확인해보면서 그 원인을 파악하고 해결할 수 있지만, 익숙하지 않은 사용자들에게는 문제를 해결하기 매우 어려운 환경이었습니다.
사용자의 실수에 대한 처리를 강하게 하지 않아서 생기는 문제, Fail-fast를 고려하지 않아 생긴 문제를 다수 확인할 수 있었습니다.
컨트리뷰션 진행
마키나락스에서도 Katib를 사용하며 비슷한 문제들을 반복해서 겪게 되었고, 단순히 Katib 를 그대로 사용하는 방식으로는 Kubernetes에 익숙하지 않은 Data Scientist와 ML Engineer가 사용하기에는 어렵다는 결론을 내리게 되었습니다.
따라서 1차적으로는 사용자가 직접 Katib Experiment의 yaml 파일을 모두 작성하는 형태가 아니라, 소수의 인터페이스만 제공하여 안전한 사용을 할 수 있도록 하였습니다. 사용자가 Experiment에 필요한 필수적인 정보만 입력하면 Experiment의 생성을 위한 yaml 파일의 대부분을 채워주는 CLI tool 을 제공하여, 안전한 사용과 더불어 Katib와 yaml 문법에 익숙하지 않은 사용자도 쉽게 접근할 수 있도록 하였습니다.
또한, 2차적으로는 Katib 레이어에서도 비정상적인 요청에 대한 케이스를 조금 더 정교하게 처리하기 위해서 직접 Katib 프로젝트에 컨트리뷰션을 진행하였습니다. 이 때, Katib Maintainer들이 문제 상황을 한 눈에 파악할 수 있도록 해당 이슈를 재현할 수 있는 명령과 스크린샷을 자세하게 첨부한 issue를 우선 생성하였으며, 이후 해당 기능을 추가한 코드와 테스트 코드를 추가한 PR을 추가하는 순서로 진행하였습니다.
이렇게 머지된 두 가지 PR에 대한 내용을 소개하겠습니다.
Experiment Naming
첫 번째로는 Experiment의 naming convention이 정해져 있었지만, 이를 체크하는 로직이 너무 뒤에 있어서 사용자의 입장에서는 생성 요청한 experiment가 CREATED 으로 영원히 멈춰있는 이슈였습니다.
우선 정확한 로그를 첨부한 issue를 생성하여, 해당 상황이 발생하지 않도록 Kubernetes의 ValidatingAdmissionWebhook에서 block 처리를 하거나, 혹은 최소한 해당 상황이 발생하면 Experiment의 status 를 FAILED로 변경하도록 수정하는 것이 어떻겠냐는 구현 방향을 함께 전달하였습니다.
이후 Katib Maintainer로부터 해당 이슈는 버그가 맞고, Fail-Fast를 위해서 ValidatingAdmissionWebhook에서 확인하는 것이 좋겠다고 동의해 주었습니다.
이후에 제가 직접 구현하고 싶다는 의사를 전달하여 구현을 시작하였고, 아래와 같이 간단한 정규 표현식을 사용해 naming convention을 검증하는 코드와 유닛 테스트를 추가한 PR을 생성하여 Maintainer의 리뷰를 거쳐 머지되었습니다.
func (g *DefaultValidator) ValidateExperiment(instance, oldInst *experimentsv1beta1.Experiment) error {
// 내부적으로 정해둔 naming convention의 정규표현식
namingConvention, _ := regexp.Compile("^[a-z]([-a-z0-9]*[a-z0-9])?")
if !namingConvention.MatchString(instance.Name) { // 검증 및 에러 처리
msg :="Name must consist of lower case alphanumeric characters or '-'," +
" start with an alphabetic character, and end with an alphanumeric character" +
" (e.g. 'my-name', or 'abc-123', regex used for validation is '[a-z]([-a-z0-9]*[a-z0-9])?)'"
return fmt.Errorf(msg)
}
// 이하 생략
Hyperparameter Search Algorithm Setting
두 번째로는 Experiment에서 hyperparameter search algorithm을 선택할 때, validation 로직이 없는 algorithm에 잘못된 세팅값을 설정한 경우, Experiment가 RUNNING으로 영원히 멈춰있는 이슈였습니다. Katib에서도 해당 issue를 파악하고 있었지만, 약 1 년째 진행되지 않고 open & frozen 상태로 남아있는 상황이었습니다.
마키나락스에서도 bayesian optimization algorithm으로 hyperparameter search 를 수행하는 실험을 진행하던 중 동일한 문제 상황을 겪었기에, 프로젝트에 직접 기여하기로 결정하였습니다.
먼저 Katib 프로젝트의 해당 이슈에 조금 더 자세한 이슈 상황을 요청하는 답글을 남겼고, Katib 의 Maintainer 중 한 명인 @andreyvelich가 친절하고 빠르게 답변해주어 소스코드 상의 어디가 문제인지, 어떻게 고쳐야 하는지에 대해 보다 빠르게 파악할 수 있었습니다.
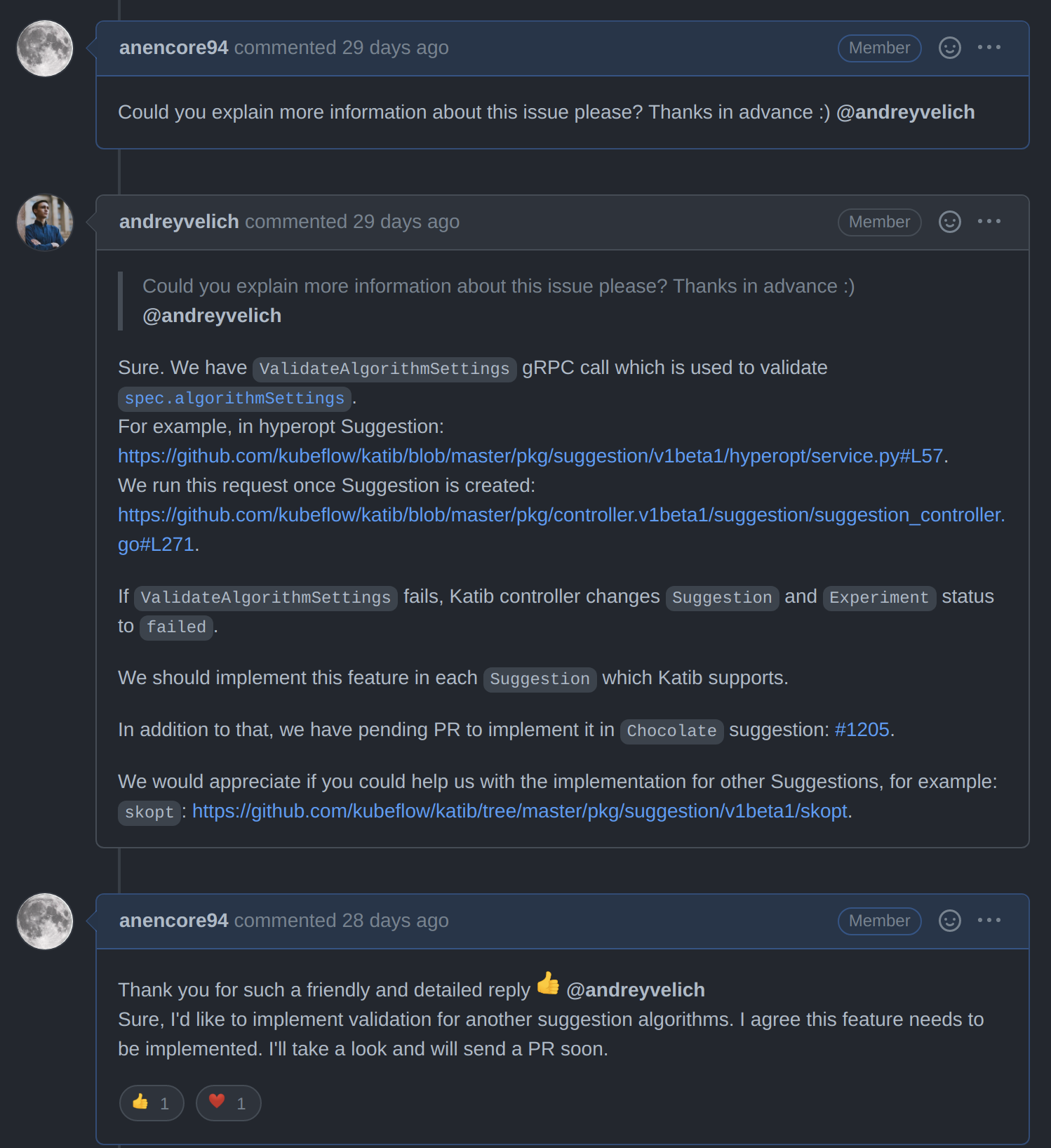
요약하면 Katib에서 제공하는 hyperparameter search algorithm 중 Hyperopt는 다음과 같이 algorithm 의 validation 과정을 제공하고 있었지만, Scikit-Optimize (이하 skopt)를 비롯한 일부 algorithm은 validation 과정을 제공하고 있지 않는다는 문제였습니다.
따라서 이를 해결하기 위해 우선 skopt의 optimizer 관련 공식 API 문서를 보며 skopt에서 필요한 validation이 무엇인지 확인하였습니다. 이후 해당 validation을 수행하는 로직을 추가하고, 가능한 테스트 케이스를 모두 검증하는 유닛 테스트를 추가한 PR을 작성하였습니다.
- 메인 로직
class SkoptService(api_pb2_grpc.SuggestionServicer, HealthServicer):
# 중간 생략
# api_pb2_grpc.SuggestionServicer 의 인터페이스를 맞추기 위한 파트
def ValidateAlgorithmSettings(self, request, context):
# OptimizerConfiguration.validate_algorithm_spec() 에 메인 로직이 있습니다.
is_valid, message = OptimizerConfiguration.validate_algorithm_spec(
request.experiment.spec.algorithm)
if not is_valid:
context.set_code(grpc.StatusCode.INVALID_ARGUMENT)
context.set_details(message)
logger.error(message)
return api_pb2.ValidateAlgorithmSettingsReply()
class OptimizerConfiguration(object):
# 중간 생략
@classmethod
def validate_algorithm_spec(cls, algorithm_spec):
algo_name = algorithm_spec.algorithm_name
# skopt 에서 지원하는 알고리즘과 일치하는지 검증합니다. 일치한다면 자세한 검증을 수행합니다.
if algo_name == "bayesianoptimization":
return cls._validate_bayesianoptimization_setting(algorithm_spec.algorithm_settings)
else:
return False, "unknown algorithm name {}".format(algo_name)
# skopt 관련 자세한 검증을 수행하는 파트
@classmethod
def _validate_bayesianoptimization_setting(cls, algorithm_settings):
for s in algorithm_settings:
try:
# 사용자가 요청한 algorithm_settings이 유효한지 각각의 attribute에 대해 검증합니다.
if s.name == "base_estimator":
if s.value not in ["GP", "RF", "ET", "GBRT"]:
return False, "base_estimator {} is not supported in Bayesian optimization".format(s.value)
elif s.name == "n_initial_points":
if not (int(s.value) >= 0):
return False, "n_initial_points should be great or equal than zero"
# 중간 생략
else:
return False, "unknown setting {} for algorithm bayesianoptimization".format(s.name)
except Exception as e:
return False, "failed to validate {name}({value}): {exception}".format(name=s.name, value=s.value,
exception=e)
return True, ""
- 유닛 테스트 코드
def test_validate_algorithm_settings(self):
# 중간 생략
# 각각의 attribute에 대해 invalid한 케이스를 모두 검증합니다.
# invalid cases
# unknown algorithm name
experiment_spec[0] = api_pb2.ExperimentSpec(
algorithm=api_pb2.AlgorithmSpec(algorithm_name="unknown"))
_, _, code, details = call_validate()
self.assertEqual(code, grpc.StatusCode.INVALID_ARGUMENT)
self.assertEqual(details, 'unknown algorithm name unknown')
# unknown config name
experiment_spec[0] = api_pb2.ExperimentSpec(
algorithm=api_pb2.AlgorithmSpec(
algorithm_name="bayesianoptimization",
algorithm_settings=[
api_pb2.AlgorithmSetting(name="unknown_conf", value="1111")]
))
_, _, code, details = call_validate()
self.assertEqual(code, grpc.StatusCode.INVALID_ARGUMENT)
self.assertEqual(details, 'unknown setting unknown_conf for algorithm bayesianoptimization')
# unknown base_estimator
experiment_spec[0] = api_pb2.ExperimentSpec(
algorithm=api_pb2.AlgorithmSpec(
algorithm_name="bayesianoptimization",
algorithm_settings=[
api_pb2.AlgorithmSetting(name="base_estimator", value="unknown estimator")]
))
_, _, code, details = call_validate()
wrong_algorithm_setting = experiment_spec[0].algorithm.algorithm_settings[0]
self.assertEqual(code, grpc.StatusCode.INVALID_ARGUMENT)
self.assertEqual(details,
"{name} {value} is not supported in Bayesian optimization".format(
name=wrong_algorithm_setting.name,
value=wrong_algorithm_setting.value))
# 이하 생략
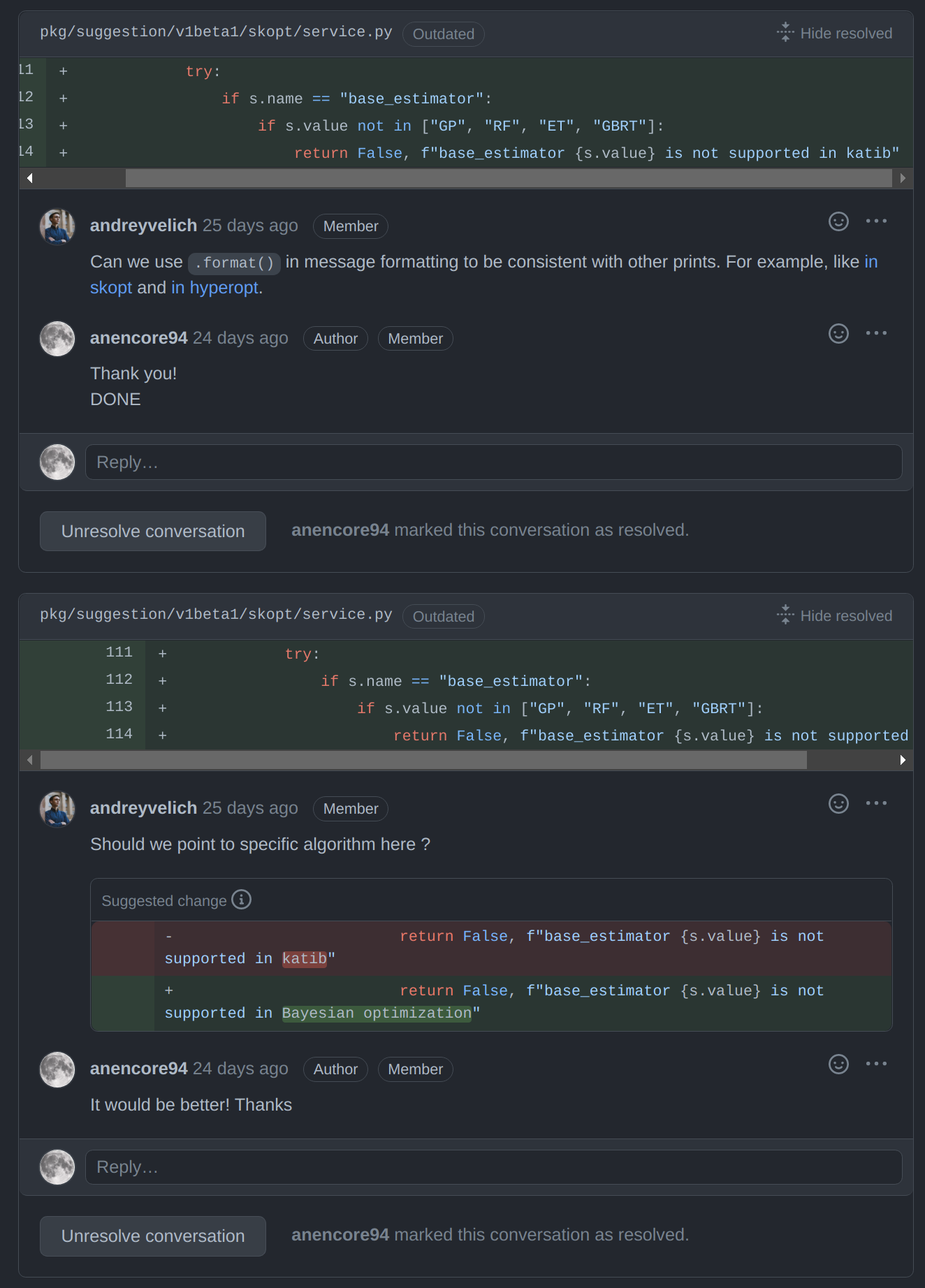
이후 다음과 같이 Maintainer로부터 Katib 내의 convention 통일, 에러 메시지를 명시적으로 수정하는 등의 리뷰를 거쳐 머지되었습니다.
맺음말
위에서 다룬 PR 외에도 마키나락스에서 Kubeflow/Katib를 비롯해 Kubeflow/kubeflow, Kubeflow/pipeline 등 Kubeflow 관련 프로젝트들을 활용하며 만났던 이슈들과 그 해결책들을 지속적으로 제시하다 보니, 기존 Kubeflow member의 추천을 받아 Kubeflow organization의 member로 합류하게 되었습니다.
마키나락스에서는 Kubeflow 외에도 다양한 오픈소스들을 적극적으로 활용하고 있으며, 단순한 사용자에 그치기보다는 오픈소스로부터 받았던 도움을 다시 커뮤니티에 돌려주는 컨트리뷰터가 되기를 장려하고 있습니다. 저 또한 앞으로 Kubeflow member 로써 더 적극적인 기여를 지속하는 것을 목표로 하고 있습니다.
오픈소스를 사용하다 보면 언제든지 문제상황에 봉착할 수 있습니다. 그리고 이때 누구나 문제에 대한 해결책을 제안할 수 있습니다. 오픈소스의 장점은 자유로운 기여를 통해 누구나 커뮤니티에 더 나은 도구를 제공할 수 있다는 것입니다.
That is the beauty of contributing to Open-Source
Explore more

오픈소스(RLlib) 문제 발견부터 컨트리뷰션까지
마키나락스의 OLP(Off-line Programming) 팀에서는 제조 공장에서 사용되는 Multi-Robot Arm의 경로계획(Path Planning) 문제를 강화학습을 이용하여 풀고 있습니다. 경로계획은 다수의 로봇팔이 효과적으로...

Comments