Kubernetes기반의 Regression Test Pipeline을 구축하기

마키나락스는 AI 기술개발을 넘어서 AI 제품화과정으로 나아가고 있습니다. 제품화과정으로 나아가는 여정 속에서 재미있는 엔지니어링 이슈들이 생겼습니다. 제품의 실체화에 가까워질수록 시장에서 발생하는 요구사항을 지속적으로 빠르게 반영해야 합니다. 이를 위해 Machine Learning Software의 신속하고 정확한 성능 검증을 필요로 하게 되었습니다. 유닛테스트 검증만으로 모델의 학습성능에 대한 검증이 어려우므로, 성능검증에 대한 다른 방법이 필요했습니다.
이번 포스트에서는 Machine Learning Software에 대한 성능검증을 어떤 방식으로 진행하고 있는지 공유드리겠습니다.
Problem: Can’t find the cause of the lower performance!
우선 AI Product를 개발하며 겪었던 문제에 대해서 공유드리겠습니다.
개발자들은 작업을 완료하면 다음의 과정을 통해 코드를 병합(Merge)합니다.
- Pull-Request를 통해 작업내용을 푸쉬합니다.
- 유닛테스트로 코드를 검증합니다.
- 작업내용을 동료들이 리뷰합니다.
- 코드를 병합니다.
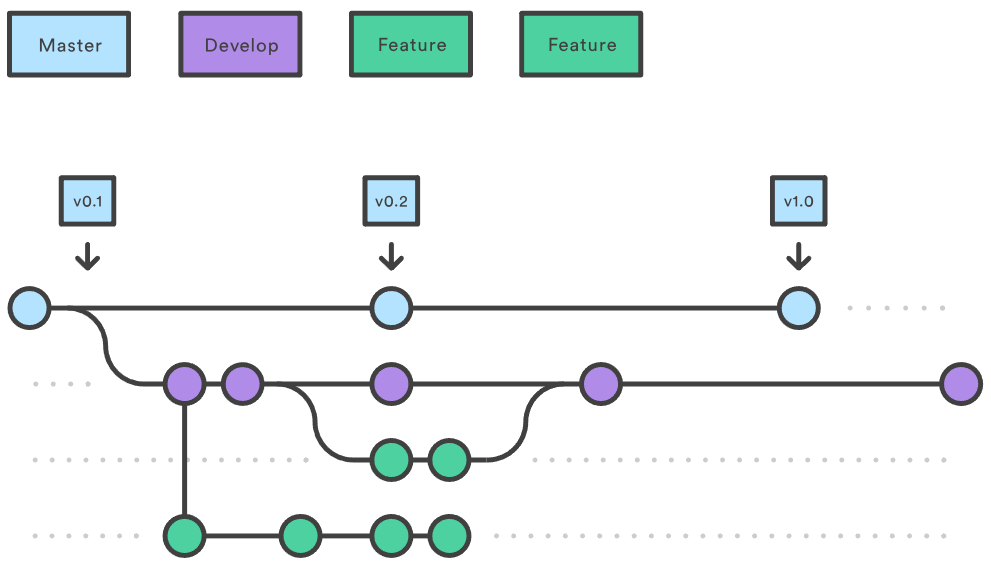
하지만 유닛테스트 만으로는 모델의 성능저하를 일으키는 변경사항을 알아챌 수 없다는 문제가 있었습니다. 예를 들어, Leaky ReLU로 사용하던 활성함수(Activation Function)를 ReLU로 변경했을때 치명적인 성능저하가 발생하였습니다. 이 경우 모델의 성능이 저하에도 불구하고 각 모듈은 설계한대로 잘 동작했으므로 모든 테스트케이스는 문제 없이 통과했습니다.
아래의 [그림2]는 실제로 겪었던 문제입니다. 여러 브랜치가 Merge된 상태에서 origin/master의 성능저하를 발견하였습니다.
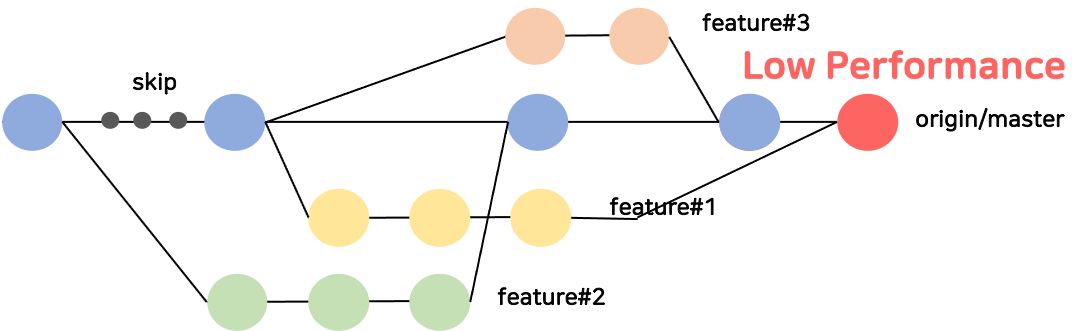
이때 어느 병합(Merge)이 성능 저하를 유발했는지 알 수 없었으므로 성능저하를 발견한 시점 이전의 변경사항을 차례대로 살펴봐야 했습니다. 즉, 당시 디버깅 해야할 커밋은 [그림3]에서 붉은색으로 음영처리된 부분이였습니다.
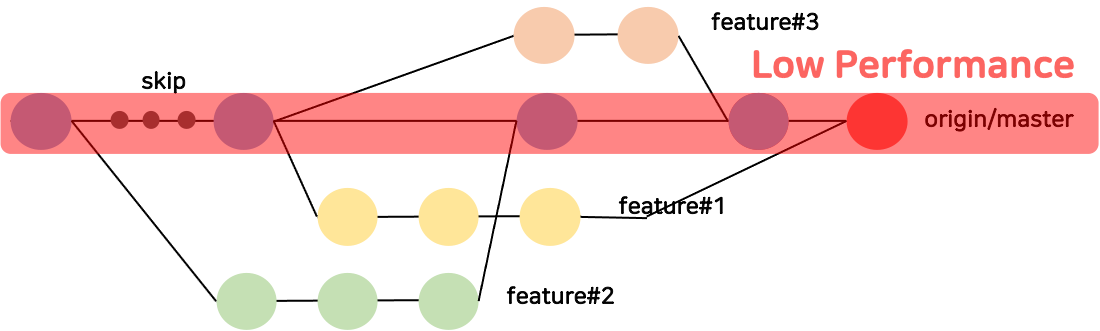
이전 히스토리를 차례대로 검증하는 작업은 매우 소모적입니다. 게다가 기민하게 시장의 요구사항을 반영해야하는 상황에서 늘어지는 디버깅 작업은 팀에 부담을 줍니다.
결국 수많은 디버깅 끝에 원인을 찾을 수 있었습니다. 그리고 원인들은 생각보다 사소한 변화였습니다. 일반적으로 생각했을때 큰 문제를 야기할 것이라고 생각하기 어려운 부분이였습니다. 아마도 그렇기 때문에 뒤늦게 발견이 되었을 것이라고 생각합니다. 더욱이 이런 커밋들이 모두 유닛테스트를 통과했기 때문에 개발자 입장에서 무엇이 원인인지 파악하기 힘들었습니다.
이런 경험을 한 후에 Are you Sure? (이 코드 문제가 없을까요?)라는 질문에 답하기 위해서는 사실상 작은 변화라고 하더라도 Regression Test를 진행해야 하는 것을 깨달았습니다.
여기서 Regression Test라고 정의한 것은 Machine Learning Software의 전체적인 학습 및 테스트를 진행하고 성능을 확인하는 작업을 의미합니다.
문제는 빨리 발견할수록 해결하기 쉽습니다. 문제를 빨리 발견하기 위해서 Regression Test를 “As Soon As Possible”(가능한 빨리) 진행해야 합니다. 이를 위해서 쉽고 빠르게 Regression Test를 할 수 있도록 Regression Test Pipeline을 구성하였습니다.
Trial and Errors
Regression Test Pipeline을 만들기 위해서 여러가지 시행착오를 겪었습니다. 앞으로 소개할 과정들은 Pipeline 구축시 다른 요소에 의존성이 있던 부분을 제거하거나 효율화하는 내용입니다.
우선 자동화 도구로 GitHub Actions의 Self-Hosted Runner를 활용하였습니다 [4]. Self-Hosted Runner는 내부 자원으로 GitHub Actions의 기능들을 사용할 수 있도록 지원하는 도구입니다.
Remark: GitHub Actions and Self-Hosted Runner
GitHub Actions는 Repository에서 개발 워크플로우를 자동화, 커스터마이즈 그리고 실행을 할 수 있는 도구입니다. CI/CD를 포함한 다양한 워크플로우를 구성할 수 있습니다.
더 자세한 정보를 알고 싶으신 분들은 GitHub Actions의 Quickstart for GitHub Actions[8]을 참고하시기 바랍니다.
GitHub Actions는 사용자가 ./github/workflows 디렉토리에 GitHub Action를 위한 yml파일을 넣게 되면 작동합니다.
yml파일에 어떤 Runner를 사용할지 결정할 수 있는데, Ubuntu, Mac OS, Windows Server등 다양한 환경을 선택할 수 있습니다.
Runner가 선택되면 GitHub에서는 가상환경을 만들어 정해진 테스크를 수행합니다.
참고로 이 때의 컴퓨팅 자원은 GitHub에서 제공되는데 자원의 사용량에 따른 과금정책을 가지고 있습니다.
Self-Hosted Runner는 내부 자원을 사용하여 가상환경을 만듭니다 [4]. Self-Hosted Runner는 의도한 작업이 컴퓨팅 리소스가 많이 사용될 때 유용합니다. Regression Test는 Machine learning Software를 학습 및 테스트를 진행하므로 많은 GPU자원과 다른 컴퓨팅자원을 필요하기 때문에 내부자원을 사용하는 것이 효율적입니다.
Self-Hosted Runner는 다음 과정을 통해서 만들 수 있습니다.
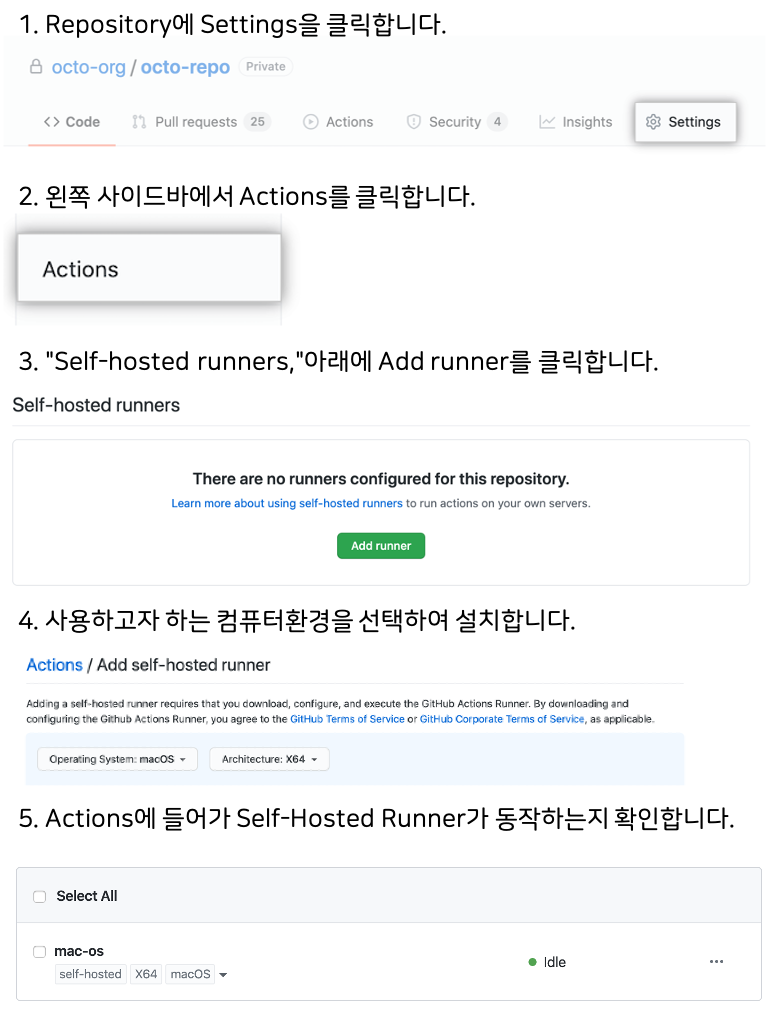
더 자세한 정보가 궁금하시다면 Adding self-hosted runners [9]를 참고하시기 바랍니다.
Self-Hosted Runner를 만들었다면 아래와 같이 선택할 수 있습니다.
name: Regression_Test
jobs:
regression_test:
runs-on: [self-hosted]
Pipeline #1: Dependent on Repository
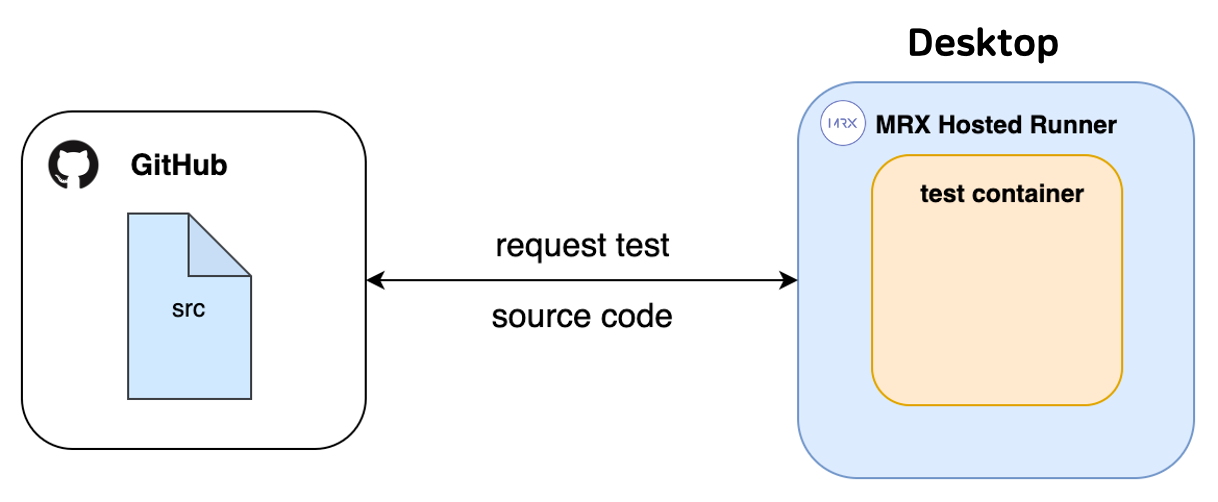
첫 번째로 구현한 Pipeline은 [그림5]에서 볼 수 있습니다. MRX-Hosted Runner가 Regression Test 대상이 되는 Repository의 Requirements(필요환경)를 미리 가지고 있습니다. 학습에 필요한 데이터의 경우 원격 저장소에 저장해두고 요청 시 접근하여 사용합니다. GitHub에서 테스트요청을 보내면 Regression Test를 진행하게 됩니다.
이런 구조는 한 Repository에 의존성을 가지게 된다는 문제를 가지고 있습니다. 특정 Repository를 위한 MRX-Hosted Runner가 다른 Repository를 운영할 수 없습니다. 한 Repository는 A 라이브러리를 사용하고 이에 맞는 MRX-Hosted Runner가 있다면, B 라이브러리가 필요한 Repository에서는 작동할 수 없습니다.
Pipeline #2: Independent from the Repository, But Inefficient
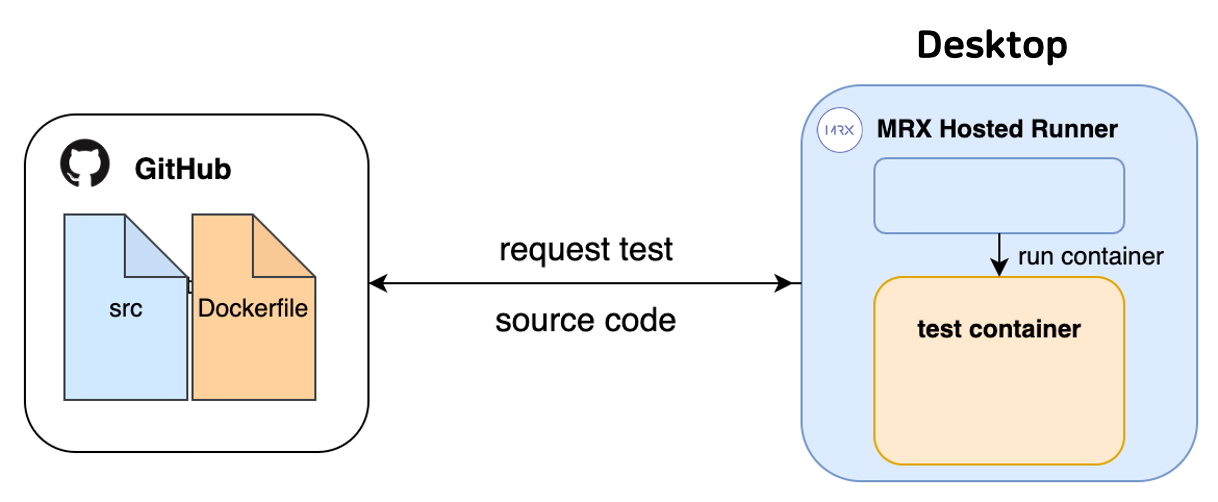
두 번째로 구현한 Pipeline은 [그림6]에서 볼 수 있습니다. Pipeline #1과 다르게 MRX-Hosted Runner가 Repository에 정의된 Dockerfile을 기반으로 Regression Test Container를 만듭니다. 이를 통해서 Repository에 의존성을 가지던 문제를 해결할 수 있었습니다. 하지만 Docker Image를 Build하는 작업은 상당히 오랜시간이 걸리며 필요한 라이브러리가 변하지 않을때도 중복적으로 Docker Image를 빌드해야합니다. Machine Learning Software의 경우 사용하는 라이브러리의 용량이 큰 것을 고려해보면 이는 상당히 비효율적입니다.
Pipeline #3: Independent from the Repository, Efficient, But!
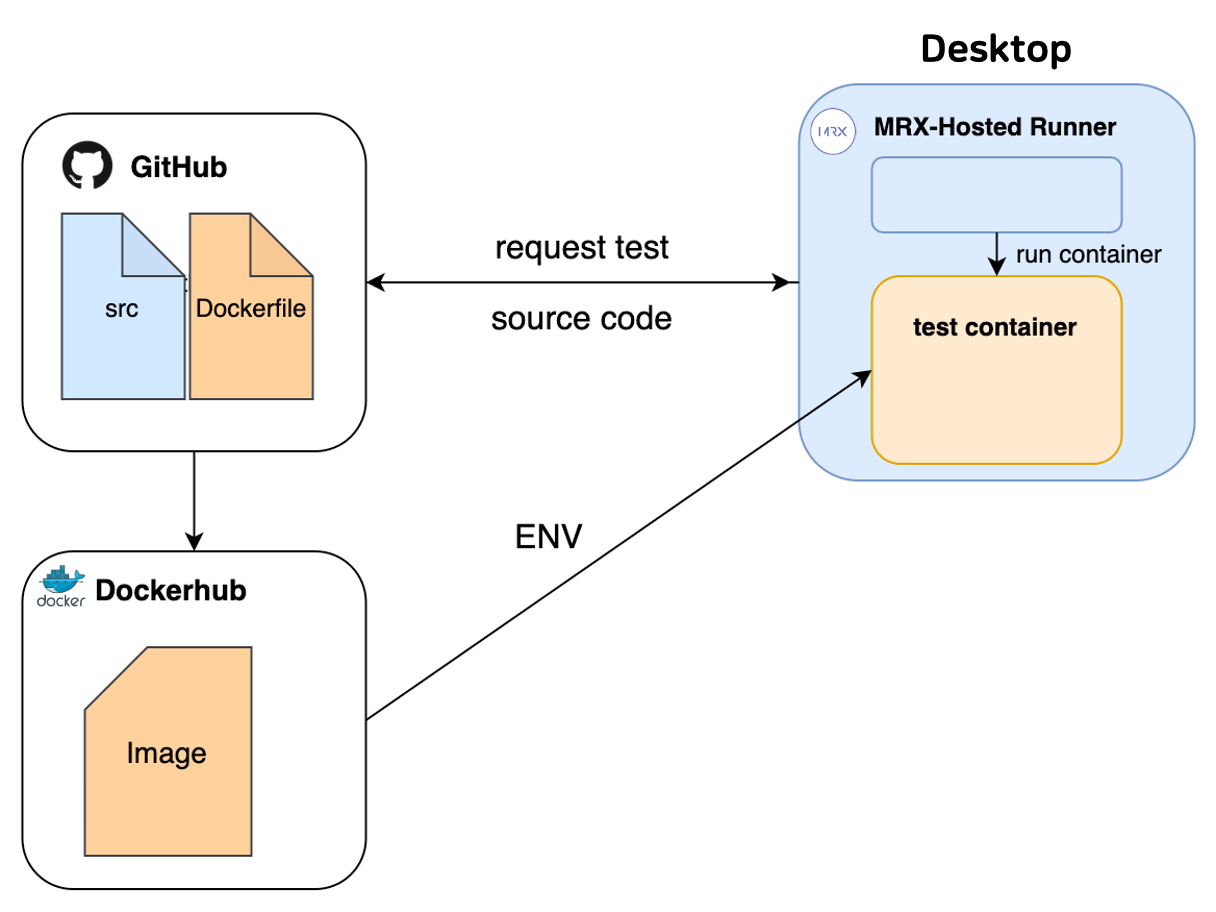
세 번째로 구현한 Pipeline은 [그림7]에서 볼 수 있습니다. Docker Image는 Requirements(필요한 라이브러리)가 변경되었을 때만 Update가 필요했습니다. Requirements는 상대적으로 변화가 적었습니다. 따라서 미리 Docker Image를 만들어 두고 MRX-Hosted Runner가 이를 받아서 사용하도록 구조를 변경하였습니다. Pipeline #2의 경우 테스트 요청마다 Docker Image를 빌드해야합니다. 반면에, Pipeline #3는 테스트 요청마다 미리 만들어둔 Docker Image를 Pull하여 사용합니다.
Resource Imbalance
하지만 Pipeline #1 ~ #3은 모두 공통적으로 한 컴퓨팅 자원에 의존적이라는 문제가 있습니다. 예를 들어 Regression Test에 사용하는 컴퓨터에서 어떤 작업을 수행하고 있다면 Regression Test의 요청이 수락되지 않거나 수행중이던 작업에 영향을 줄 수 있습니다. [그림8]를 보면 3개의 Process가 모두 동일한 하나의 서버에 접속하여 사용하고 있는 모습을 볼 수 있습니다. 붉은 색으로 표현된 것은 남은 Memory가 많지 않다는 것을 의미합니다. 만약 MRX-Hosted Runner도 동일한 서버에서 작동하고 있다면 OOM(Out-of-Memory)가 발생하여 Regression Test가 정상적으로 작동하지 않을 수 있습니다.
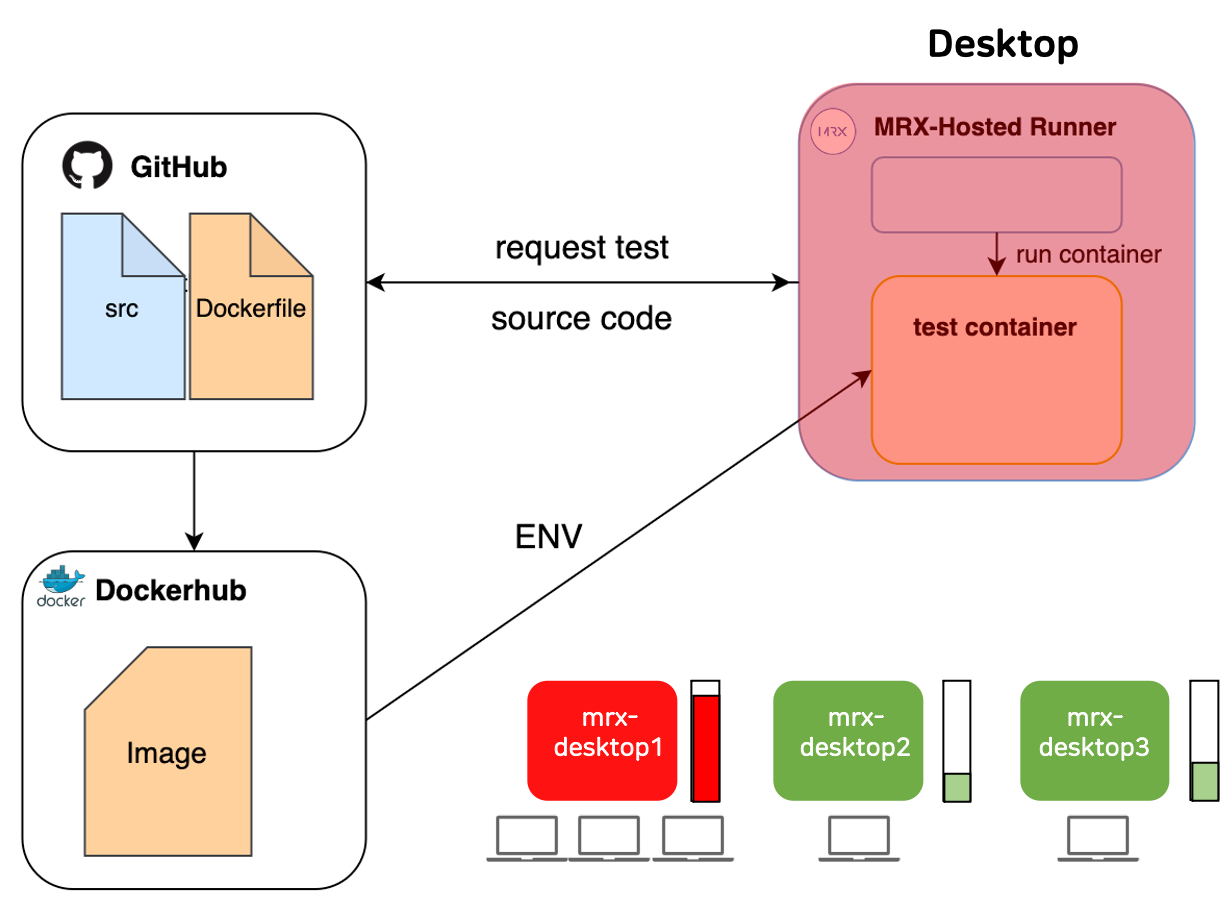
또한 다른 MRX-Desktop2, 3를 보면 컴퓨팅 자원이 여유있다는 것을 알 수 있습니다. 자원을 효율적으로 사용하기 위해서 남은 자원에 효율적으로 접근하는 것이 필요했습니다. 이를 위해서는 Regression Test Pipeline이 특정 자원에 종속되지 않고 필요한 자원에 동적으로 접근하여야 합니다. 즉, 위의 [그림8] 예시처럼 Regression Test Pipeline이 특정 자원의 영향을 받는 것을 개선해야합니다.
Pipeline #4: Independent from the Machine
Imbalance Resource를 해결하기 위해서 Kubernetes를 사용하였습니다 [2]. Kubernetes에 대해서 알고 싶으신 분들은 Kubernetes의 공식문서[6]를 참고하시는 것을 추천드립니다.
Kubernetes를 사용한 목적은 내부의 컴퓨팅 자원을 추상화하기 위함입니다. 쉽게 풀어쓰면, Kubernetes에 특정 Machine를 요청하는 것이 아니라, 필요한 컴퓨팅 자원에 대해서 요청만 하면, 그에 맞는 자원할당을 받기 위해서입니다. [그림9]을 보면 여러가지 컴퓨팅 자원이 하나의 클러스터로 묶여있습니다. 이제 원하는 자원의 스펙을 적으면, 그에 맞는 자원이 할당될 것입니다.

Remark: Kubernetes
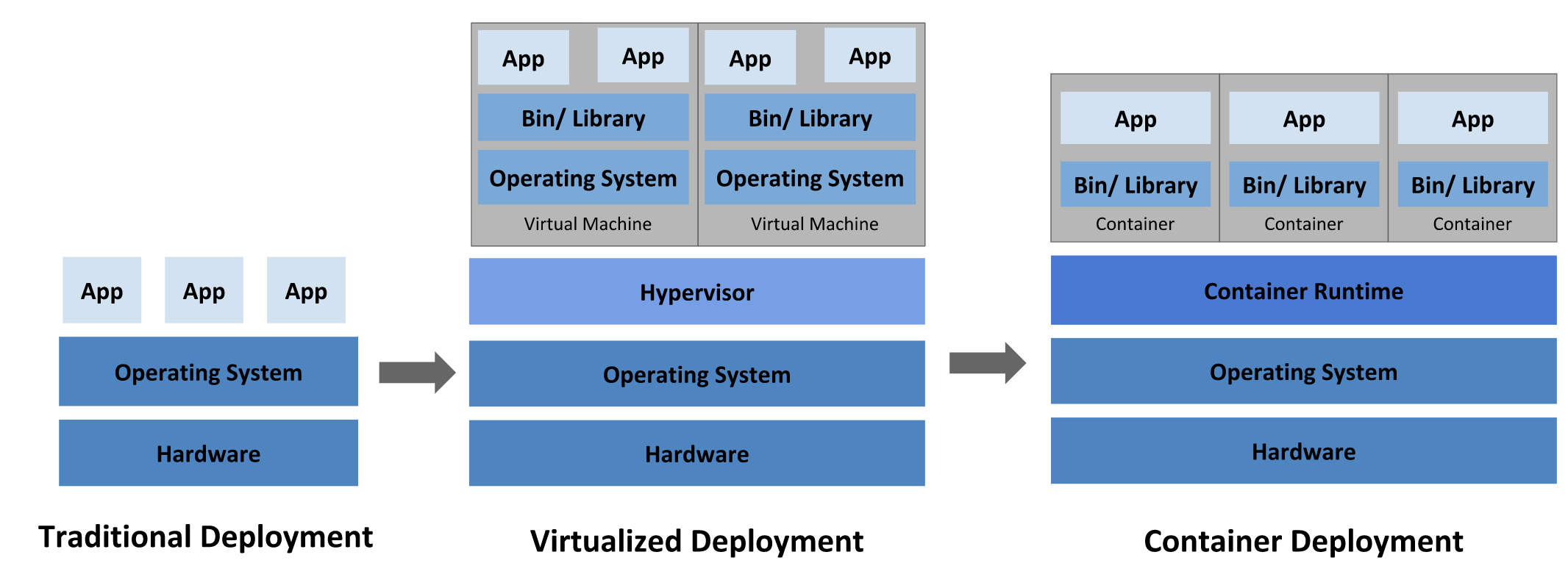
Kubernetes는 Container Orchestration을 위한 도구입니다. Container는 VM과 비교했을 때 격리 속성을 완화하여 애플리케이션 간에 운영체제를 공유합니다. 따라서 VM보다 더 가볍게 이용할 수 있습니다. Container에 대한 관심이 많아지자 자연스럽게 Container Orchestration에 대한 필요성도 강조되었습니다. Container를 쉽고 효율적으로 관리하기 위한 도구 중 하나가 Kubernetes입니다. 프로덕션 환경에서 애플리케이션을 실행하는 컨테이너가 정상작동하는지 확인하고 다운되었다면 다른 컨테이너를 실행해야합니다. Kubernetes를 활용하면 이런 문제를 시스템에 의해서 자동으로 처리할 수 있습니다 [2].
또한 Kubernetes에서는 여러 노드(컴퓨팅 자원)를 묶어서 Cluster를 구성할 수 있습니다. Cluster로 묶인 노드의 집합은 하나의 큰 컴퓨팅 자원처럼 사용될 수 있습니다. Kubernetes의 도입으로 특정 노드에 직접 접근할 필요가 없어졌고 하나의 노드에 작업이 집중되는 것을 막을 수 있었습니다.
Remark: Ray Cluster
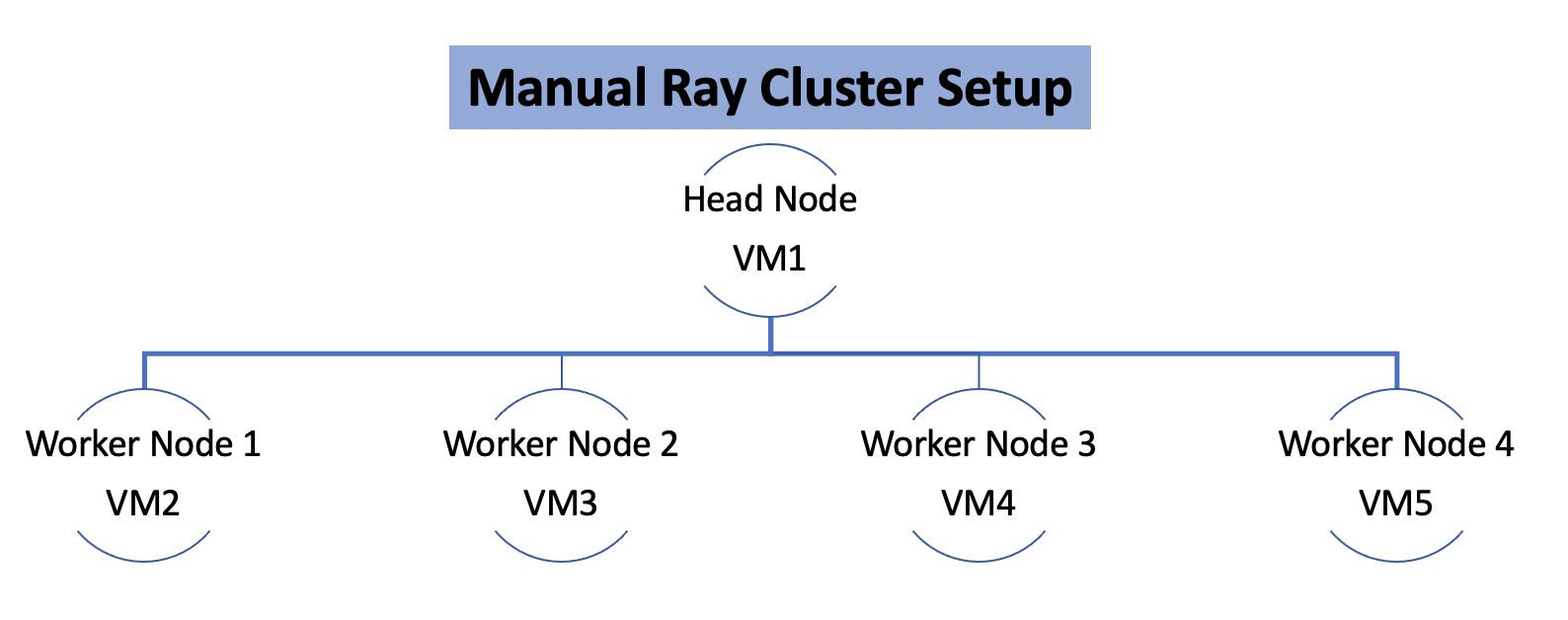
Regression Test를 하는데 너무 많은 시간이 소요된다면 업무의 병목이 될 수 있습니다. Ray Cluster는 병렬로 실험을 진행하기 때문에 Regression Test에 걸리는 시간을 줄일 수 있습니다.
Ray Cluster는 헤드 노드와 워커 노드로 구성됩니다. 헤드 노드에서는 작업들을 워커 노드에 분배하여 병렬로 테스크를 수행합니다. Ray Cluster는 작업들을 병렬적으로 처리하여 Regression Test를 빠르게 진행할 수 있습니다. Ray Autoscaler는 Cluster의 자원상황을 고려하여 워커 노드의 개수를 동적으로 조절할 수 있습니다 [3].
MRX-Hosted Runner의 역할은 특정 Machine내에서 Container로 Regression Test를 진행하는 것이 아닙니다. 미리 정의된 컴퓨팅 자원 스펙에 해당하는 Ray Cluster를 만드는 것입니다 [3]. 여기서 Ray Cluster의 역할은 Regression Test를 병렬적으로 진행하기 위한 목적으로 사용되고 작업이 끝나게 되면 Ray Cluster는 사라지게 됩니다. 참고로 [그림9]에서 구성한 Cluster와 Ray Cluster는 다른 역할을 합니다. [그림9]은 자원자체를 묶는 작업을 의미한다면 Ray Cluster는 이미 묶인 자원을 활용하는 것입니다.
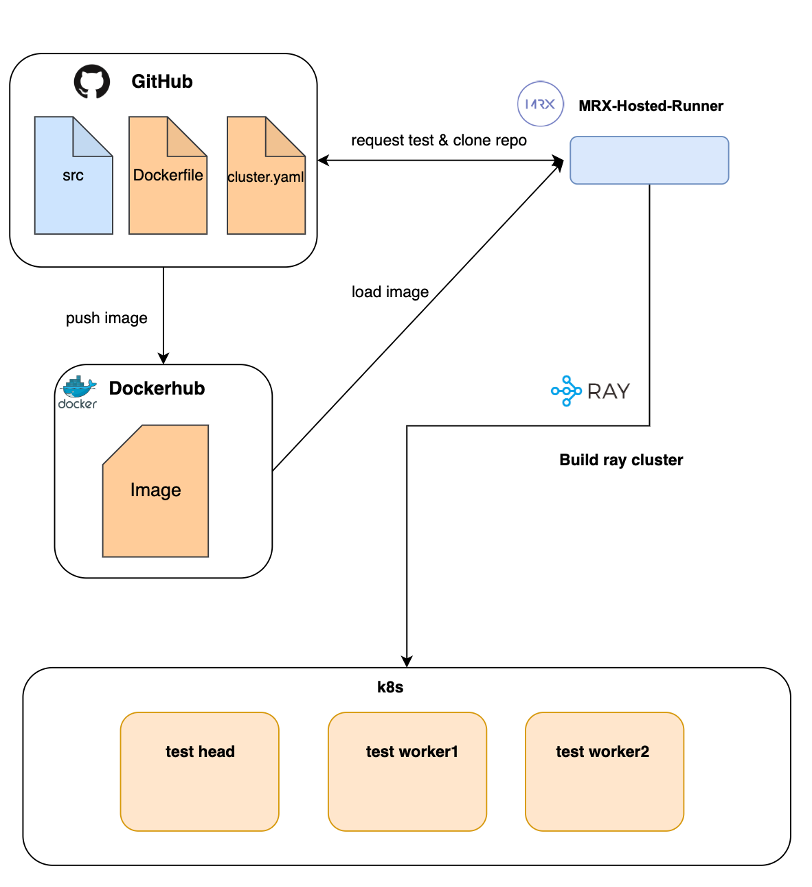
이제 Kubernetes 그리고 Ray Cluster를 활용하여 [그림12]과 같은 Pipeline을 구축하였습니다. Repository에 의존성을 제거하였으며 Docker Image도 미리 만들어둔 Image를 활용하였습니다. 또한 Machine에 대한 의존성을 제거하여 내부의 컴퓨팅 자원을 더욱 효율적으로 사용할 수 있었습니다.
Are You Sure? Yes!
GitHub Action에서 Trigger Event Type에 대해서 정할 수 있습니다. 여러 논의 끝에 Pull Request의 리뷰가 완료되었을 때 테스트가 수행되거나 또는 필요시 테스트 수행을 요청할 수 있도록 설정하였습니다. 이를 위해서 GitHub Actions의 Pull Request Review와 Workflow Dispatch Event를 사용하였습니다. 또한 Regression Test가 최신 브랜치기준으로 실행하는 것을 강제하기 위해서 ‘Require branches to be up to date before merging’ 옵션을 선택하였습니다.
개발자들이 코드를 병합하는 과정은 다음과 같이 변경되었습니다.
- Pull-Request를 통해 작업내용을 푸쉬합니다.
- 유닛테스트로 코드를 검증합니다.
- (Optional: Workflow Dispatch) PR내용에 따라 Regression Test로 성능을 검증합니다.
- 작업내용을 동료들이 리뷰합니다.
- (Automatically: Pull Request Review) Regression Test로 성능을 검증합니다.
- 코드를 병합니다.
Remark: GitHub Actions Event Type
GitHub Actions는 특정 이벤트에 대하여 정해진 테스크를 수행할 수 있습니다. 예를 들어 Pull Request 이벤트가 발생할 때 테스크를 수행하고 싶다면 아래와 같이 작성하면 됩니다.
name: Regression_Test
on:
pull_request:
매 Pull Request 혹은 Push마다 Regression Test를 수행한다면 너무 많은 실험을 진행해야합니다. Regression Test는 유닛테스트보다 긴 시간이 소요되며 컴퓨팅 자원도 많이 사용합니다. 따라서 너무 많은 Regression Test는 팀에 부담을 줄 수 있습니다.
이런 문제를 해결하기 위해서 새로운 유형의 트리거 이벤트가 필요했습니다.
Workflow Dispatch는 선택적으로 GitHub Action을 수행하고 싶을 때 사용합니다 [5]. Workflow Dispatch는 수동으로 GitHub Action을 수행할 수 있으며 [그림13]와 같이 GitHub UI를 통해서 쉽게 실행할 수 있습니다.
코드리뷰가 끝난 후에 Regression Test를 수행하기 위하여 Workflow Dispatch를 선택하였습니다.
이제 마우스 클릭으로 GitHub Web에서 Regression Test를 실행할 수 있습니다.
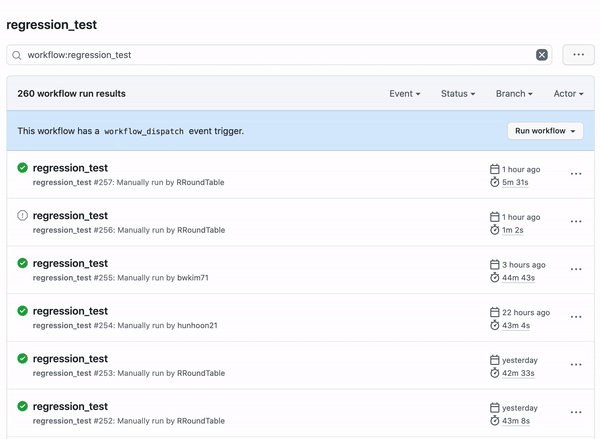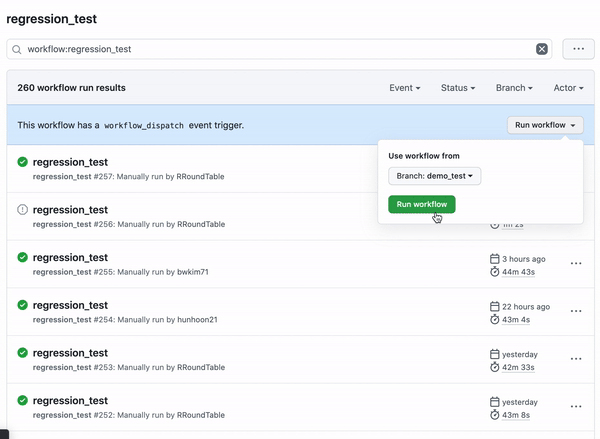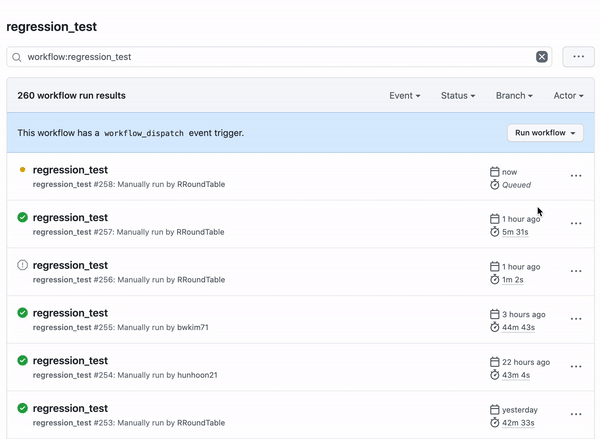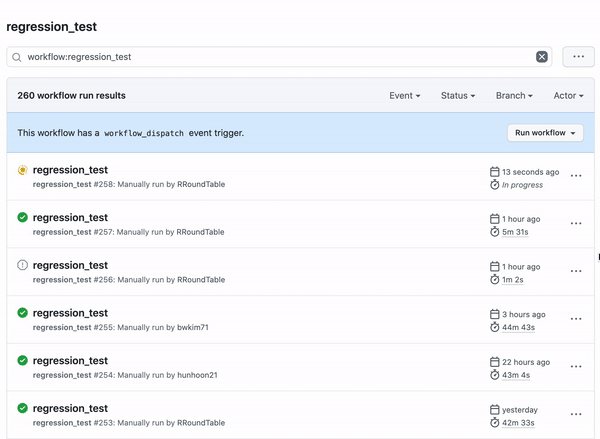
또한 Pull Request에 대한 Approve 이벤트 발생시 자동으로 실행시켜주기 위해 Pull Request Review 이벤트를 사용했습니다.
Workflow Dispatch와 Pull Request Review 트리거 이벤트를 사용하고 싶다면, 다음과 같이 작성하면 됩니다.
on:
pull_request_review:
types: [submitted]
workflow_dispatch:
jobs:
Regression_Test:
if: (github.event.review.state == 'approved' || github.event_name == 'workflow_dispatch')
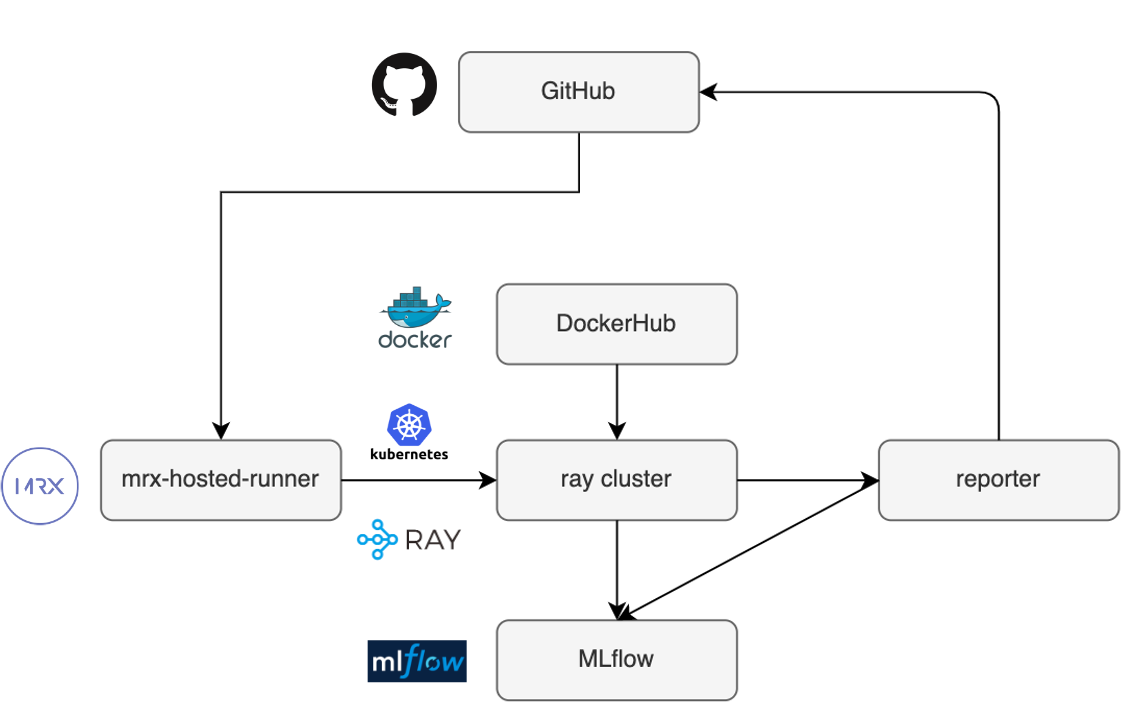
Regression Test Pipeline의 모습을 [그림14]으로 도식화했습니다. GitHub에서 미리 설정한 Event Type에 해당하는 Event가 발생하면 MRX-Hosted-Runner에게 Regression Test를 요청합니다. MRX-Hosted-Runner는 Ray Cluster를 구성합니다. 학습 및 실험을 진행할 때는 중앙화된 실험기록 서비스에 실험정보를 로깅하고 학습이 끝나면 이에 대한 정보를 GitHub에 전달합니다 [7]. 현재는 해당 PR에 Comment로 실험링크를 달아주는 방식으로 사용중입니다. 이를 통해서 팀 전체적으로 실험결과를 쉽게 확인할 수 있습니다.
Remark: GitHub Branch Protection Rule
GitHub에서는 특정 브랜치에 병합하기 위해서 필요한 상태확인(Status Check)을 지정할 수 있습니다. 이를 활용하여 Regression Test가 진행되지 않은 경우 병합을 못하도록 설정할 수 있습니다.
GitHub Branch Protection Rule은 다음과 같은 과정을 통해 설정할 수 있습니다 [12].
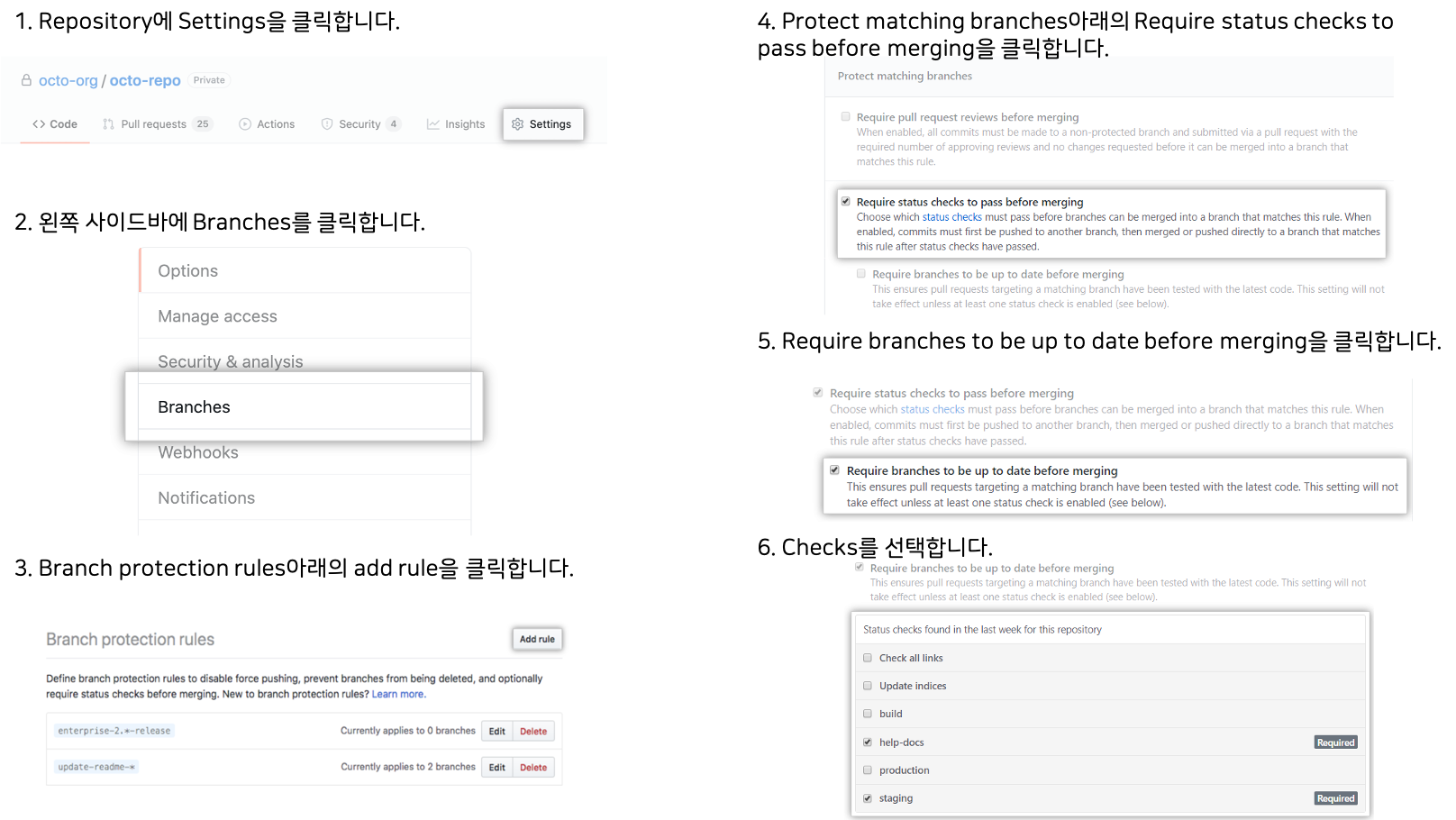
Regression Test에서 정상작동한 브랜치에 대해서 Are You Sure? 라고 누가 묻는다면 이제는 자신있게 Yes!라고 할 수 있습니다. 이런 변화는 코드변경에 대한 자신감을 키워주었고 나아가 견고하면서 빠른 협업을 가능하게 했습니다.
마치며
이번 포스팅에서는 Machine Learning Software의 Regression Test에 대해서 다뤘습니다.
코드변경으로 인해서 Machine Learning Software의 성능에 부정적 영향을 줄 수 있습니다. 하지만 유닛테스트만으로 Machine Learning Software의 성능을 검증할 수 없다는 문제가 있습니다.
문제를 해결하기 위해서 Kubernetes기반의 Regression Test Pipeline을 구축하였습니다. Repository에 독립적으로 실행할 수 있으며 많은 컴퓨팅 자원을 효율적으로 사용할 수 있습니다.
Regression Test Pipeline의 도입을 통해 코드변경에서 발생하는 문제를 빠르게 발견할 수 있었습니다. 이런 변화는 코드변경에 대한 자신감을 키워주었고 나아가 견고하면서 빠른 협업을 가능하게 했습니다.
이번 포스트를 통해서 비슷한 문제를 고민하는 분들께 작은 도움이 되었으면 좋겠습니다.
References
[1] Gitflow Workflow[websites], (2021, Mar, 22)
[2] Kubernetes[websites], (2021, Feb, 10)
[3] Ray cluster[websites], (2021, Feb, 10)
[4] About Self Hosted Runners[websites], (2021, Feb, 10)
[5] Workflow Dispatch[websites], (2021, Feb, 10)
[6] What is Kubernetes[websites], (2021, Feb, 10)
[7] MLflow[websites], (2021, Feb, 10)
[8] Quickstart for GitHub Actions[websites], (2021, Mar, 17)
[9] Adding Self-Hosted Runners[websites], (2021, Mar, 22)
[10] Tips on Installing and Maintaining Ray Cluster[websites], (2020, Mar, 22)
[11] Continuous Integration[websites], (2021, Mar, 22)
[12] Managing a branch protection rule[websites], (2021, Apr, 5)
Explore more
실시간 데이터 검증하기
마키나락스는 제조업에서 실시간으로 생산 장비와 공정의 고장 및 이상을 사전에 예측하는 이상탐지 시스템을 제공하고 있습니다. 이상탐지 시스템을 적용하고자 하는 제조...

Comments